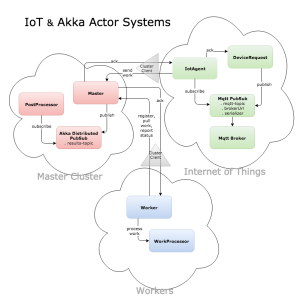
Back in 2016, I built an Internet-of-Thing (IoT) prototype system leveraging the “minimalist” design principle of the Actor model to simulate low-cost, low-powered IoT devices. A simplified version of the prototype was published in a previous blog post. The stripped-down application was written in Scala along with the Akka Actors run-time library, which is arguably the predominant Actor model implementation at present. Message Queue Telemetry Transport (MQTT) was used as the publish-subscribe messaging protocol for the simulated IoT devices. For simplicity, a single actor was used to simulate requests from a bunch of IoT devices.
In this blog post, I would like to share a version closer to the design of the full prototype system. With the same tech stack used in the previous application, it’s an expanded version (hence, II) that uses loosely-coupled lightweight actors to simulate individual IoT devices, each of which maintains its own internal state and handles bidirectional communications via non-blocking message passing. Using a distributed workers system adapted from a Lightbend template along with a persistence journal, the end product is an IoT system equipped with a scalable fault-tolerant data processing system.
Main components
Below is a diagram and a summary of the revised Scala application which consists of 3 main components:
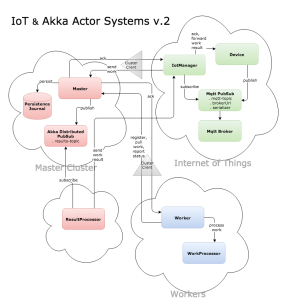
1. IoT
- An IotManager actor which:
- instantiates a specified number of devices upon start-up
- subscribes to a MQTT pub-sub topic for the work requests
- sends received work requests via ClusterClient to the master cluster
- notifies Device actors upon receiving failure messages from Master actor
- forwards work results to the corresponding devices upon receiving them from ResultProcessor
- Device actors each of which:
- simulates a thermostat, lamp, or security alarm with random initial state and setting
- maintains and updates internal state and setting upon receiving work results from IotManager
- generates work requests and publishes them to the MQTT pub-sub topic
- re-publishes requests upon receiving failure messages from IotManager
- A MQTT pub-sub broker and a MQTT client for communicating with the broker
- A configuration helper object, MqttConfig, consisting of:
- MQTT pub-sub topic
- URL for the MQTT broker
- serialization methods to convert objects to byte arrays, and vice versa
2. Master Cluster
- A fault-tolerant decentralized cluster which:
- manages a singleton actor instance among the cluster nodes (with a specified role)
- delegates ClusterClientReceptionist on every node to answer external connection requests
- provides fail-over of the singleton actor to the next-oldest node in the cluster
- A Master singleton actor which:
- registers Workers and distributes work to available Workers
- acknowledges work request reception with IotManager
- publishes work results from Workers to ‘work-results’ topic via Akka distributed pub-sub
- maintains work states using persistence journal
- A ResultProcessor actor in the master cluster which:
- gets instantiated upon starting up the IoT system (more on this below)
- consumes work results by subscribing to the ‘work-results’ topic
- sends work results received from Master to IotManager
3. Workers
- An actor system of Workers each of which:
- communicates via ClusterClient with the master cluster
- registers with, pulls work from the Master actor
- reports work status with the Master actor
- instantiates a WorkProcessor actor to perform the actual work
- WorkProcessor actors each of which:
- processes the work requests from its parent Worker
- generates work results and send back to Worker
Master-worker system with a ‘pull’ model
While significant changes have been made to the IoT actor system, much of the setup for the Master/Worker actor systems and MQTT pub-sub messaging remains largely unchanged from the previous version:
- As separate independent actor systems, both the IoT and Worker systems communicate with the Master cluster via ClusterClient.
- Using a ‘pull’ model which generally performs better at scale, the Worker actors register with the Master cluster and pull work when available.
- Paho-Akka is used as the MQTT pub-sub messaging client.
- A helper object, MqttConfig, encapsulates a MQTT pub-sub topic and broker information along with serialization methods to handle MQTT messaging using a test Mosquitto broker.
What’s new?
Now, let’s look at the major changes in the revised application:
First of all, Lightbend’s Activator has been retired and Sbt is being used instead.
On persisting actors state, a Redis data store is used as the persistence journal. In the previous version the shared LevelDB journal is coupled with the first seed node which becomes a single point of failure. With the Redis persistence journal decoupled from a specific cluster node, fault tolerance steps up a notch.
As mentioned earlier in the post, one of the key changes to the previous application is the using of actors representing individual IoT devices each with its own state and capability of communicating with entities designated for interfacing with external actor systems. Actors, lightweight and loosely-coupled by design, serve as an excellent vehicle for modeling individual IoT devices. In addition, non-blocking message passing among actors provides an efficient and economical means for communication and logic control of the device state.
The IotManager actor is responsible for creating and managing a specified number of Device actors. Upon startup, the IoT manager instantiates individual Device actors of random device type (thermostat, lamp or security alarm). These devices are maintained in an internal registry regularly updated by the IoT manager.
Each of the Device actors starts up with a random state and setting. For instance, a thermostat device may start with an ON state and a temperature setting of 68F whereas a lamp device might have an initial state of OFF and brightness setting of 2. Once instantiated, a Device actor will maintain its internal operational state and setting from then on and will report and update the state and setting per request.
Work and WorkResult
In this application, a Work object represents a request sent by a specific Device actor and carries the Device’s Id and its current state and setting data. A WorkResult object, on the other hand, represents a returned request for the Device actor to update its state and setting stored within the object.
Responsible for processing the WorkResult generated by the Worker actors, the ResultProcessor actor simulates the processing of work result – in this case it simply sends via the actorSelection method the work result back to the original Device actor through IotManager. Interacting with only the Master cluster system as a cluster client, the Worker actors have no knowledge of the ResultProcessor actor. ResultProcessor receives the work result through subscribing to the Akka distributed pub-sub topic which the Master is the publisher.
While a participant of the Master cluster actor system, the ResultProcessor actor gets instantiated when the IoT actor system starts up. The decoupling of ResultProcessor instantiation from the Master cluster ensures that no excessive ResultProcessor instances get started when multiple Master cluster nodes start up.
Test running the application
Complete source code of the application is available at GitHub.
To run the application on a single JVM, just git-clone the repo, run the following command at a command line terminal and observe the console output:
# Start a Redis server accessible to the master cluster to serve as the persistence journal:
$ nohup redis-server /path/to/conf &
# Launch the master cluster with 2 seed nodes, IoT actor system and Worker actor system:
$ cd {project-root}
$ bin/sbt "runMain akkaiot.Main [NumOfDevices]"
The optional NumOfDevices parameter defaults to 20.
To run the application on separate JVMs, git-clone the repo to a local disk, open up separate command line terminals and launch the different components on separate terminals:
# Start a Redis server accessible to the master cluster to serve as the persistence journal:
$ nohup redis-server /path/to/conf &
cd {project-root}
# Launch the master cluster seed node with persistence journal:
$ bin/sbt "runMain akkaiot.Main 2551"
# Launch additional master cluster seed node:
$ bin/sbt "runMain akkaiot.Main 2552"
# Launch the IoT node:
$ bin/sbt "runMain akkaiot.Main 3001 [NumOfDevices]"
# Launch a Worker node:
$ bin/sbt "runMain akkaiot.Main 0"
# Launch additional Worker node:
$ bin/sbt "runMain akkaiot.Main 0"
Sample console log
Below is filtered console log output from the console tracing the evolving state and setting of a thermostat device:
# ### Console log filtered for device thermostat-1015 # [info] [INFO] [07/12/2017 14:38:44.707] [IotSystem-akka.actor.default-dispatcher-21] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> thermostat-1015 started [info] [INFO] [07/12/2017 14:38:49.726] [IotSystem-akka.actor.default-dispatcher-29] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> thermostat-1015 with state 0 created work (Id: 69d82872-a9f4-492e-8ae4-28229b797994) [info] [INFO] [07/12/2017 14:38:49.726] [IotSystem-akka.actor.default-dispatcher-29] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Publishing MQTT Topic akka-iot-mqtt-topic: Device thermostat-1015 [info] [INFO] [07/12/2017 14:38:49.915] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager] IoT Agent -> Received MQTT message: thermostat-1015 | State 0 | Setting 70 [info] [INFO] [07/12/2017 14:38:50.261] [ClusterSystem-akka.actor.default-dispatcher-3] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work for thermostat-1015 : Work Id 69d82872-a9f4-492e-8ae4-28229b797994 [info] [INFO] [07/12/2017 14:38:50.265] [IotSystem-akka.actor.default-dispatcher-16] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Work for thermostat-1015 accepted | Work Id 69d82872-a9f4-492e-8ae4-28229b797994 [info] [INFO] [07/12/2017 14:38:50.488] [ClusterSystem-akka.actor.default-dispatcher-25] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work for thermostat-1015 to Worker 3ec3b314-1c35-4e57-92b3-41c9edb86fbc | Work Id 69d82872-a9f4-492e-8ae4-28229b797994 [info] [INFO] [07/12/2017 14:38:50.489] [WorkerSystem-akka.actor.default-dispatcher-2] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker] Worker -> Received work request from thermostat-1015 | State 0 | Setting 70 [info] [INFO] [07/12/2017 14:38:50.489] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker/work-processor] Work Processor -> thermostat-1015: Switch to COOL | LOWER temperature by -2 [info] [INFO] [07/12/2017 14:38:50.489] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker] Worker -> Processed work: thermostat-1015 | Work Id 69d82872-a9f4-492e-8ae4-28229b797994 [info] [INFO] [07/12/2017 14:38:50.493] [ClusterSystem-akka.actor.default-dispatcher-27] [akka.tcp://ClusterSystem@127.0.0.1:59407/user/result-processor] Result Processor -> Got work result: thermostat-1015 | State 2 | Setting 68 [info] [INFO] [07/12/2017 14:38:50.493] [ClusterSystem-akka.actor.default-dispatcher-27] [akka.tcp://ClusterSystem@127.0.0.1:59407/user/result-processor] Result Processor -> Sent work result for thermostat-1015 to IoT Manager [info] [INFO] [07/12/2017 14:38:50.495] [IotSystem-akka.actor.default-dispatcher-33] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager] IoT Manager -> Work result forwarded to thermostat-1015 [info] [INFO] [07/12/2017 14:38:50.495] [IotSystem-akka.actor.default-dispatcher-15] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> thermostat-1015 received work result with work Id 69d82872-a9f4-492e-8ae4-28229b797994. [info] [INFO] [07/12/2017 14:38:50.495] [IotSystem-akka.actor.default-dispatcher-15] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Updated thermostat-1015 with state 2 and setting 68. [info] [INFO] [07/12/2017 14:38:55.275] [IotSystem-akka.actor.default-dispatcher-16] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> thermostat-1015 with state 2 created work (Id: df9622cd-6b80-42e9-be1b-f0a92d002d75) [info] [INFO] [07/12/2017 14:38:55.275] [IotSystem-akka.actor.default-dispatcher-16] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Publishing MQTT Topic akka-iot-mqtt-topic: Device thermostat-1015 [info] [INFO] [07/12/2017 14:38:55.578] [IotSystem-akka.actor.default-dispatcher-15] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager] IoT Agent -> Received MQTT message: thermostat-1015 | State 2 | Setting 68 [info] [INFO] [07/12/2017 14:38:55.580] [ClusterSystem-akka.actor.default-dispatcher-25] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work for thermostat-1015 : Work Id df9622cd-6b80-42e9-be1b-f0a92d002d75 [info] [INFO] [07/12/2017 14:38:55.583] [IotSystem-akka.actor.default-dispatcher-16] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Work for thermostat-1015 accepted | Work Id df9622cd-6b80-42e9-be1b-f0a92d002d75 [info] [INFO] [07/12/2017 14:38:55.586] [ClusterSystem-akka.actor.default-dispatcher-19] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work for thermostat-1015 to Worker 3ec3b314-1c35-4e57-92b3-41c9edb86fbc | Work Id df9622cd-6b80-42e9-be1b-f0a92d002d75 [info] [INFO] [07/12/2017 14:38:55.587] [WorkerSystem-akka.actor.default-dispatcher-3] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker] Worker -> Received work request from thermostat-1015 | State 2 | Setting 68 [info] [INFO] [07/12/2017 14:38:55.587] [WorkerSystem-akka.actor.default-dispatcher-3] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker/work-processor] Work Processor -> thermostat-1015: Keep state COOL | LOWER temperature by -2 [info] [INFO] [07/12/2017 14:38:55.587] [WorkerSystem-akka.actor.default-dispatcher-3] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker] Worker -> Processed work: thermostat-1015 | Work Id df9622cd-6b80-42e9-be1b-f0a92d002d75 [info] [INFO] [07/12/2017 14:38:55.590] [ClusterSystem-akka.actor.default-dispatcher-22] [akka.tcp://ClusterSystem@127.0.0.1:59407/user/result-processor] Result Processor -> Got work result: thermostat-1015 | State 2 | Setting 66 [info] [INFO] [07/12/2017 14:38:55.590] [ClusterSystem-akka.actor.default-dispatcher-22] [akka.tcp://ClusterSystem@127.0.0.1:59407/user/result-processor] Result Processor -> Sent work result for thermostat-1015 to IoT Manager [info] [INFO] [07/12/2017 14:38:55.591] [IotSystem-akka.actor.default-dispatcher-18] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager] IoT Manager -> Work result forwarded to thermostat-1015 [info] [INFO] [07/12/2017 14:38:55.591] [IotSystem-akka.actor.default-dispatcher-16] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> thermostat-1015 received work result with work Id df9622cd-6b80-42e9-be1b-f0a92d002d75. [info] [INFO] [07/12/2017 14:38:55.591] [IotSystem-akka.actor.default-dispatcher-16] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Updated thermostat-1015 with state 2 and setting 66. [info] [INFO] [07/12/2017 14:39:01.596] [IotSystem-akka.actor.default-dispatcher-15] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> thermostat-1015 with state 2 created work (Id: c57d21af-3957-43ba-a995-f4f558900fa3) [info] [INFO] [07/12/2017 14:39:01.597] [IotSystem-akka.actor.default-dispatcher-15] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Publishing MQTT Topic akka-iot-mqtt-topic: Device thermostat-1015 [info] [INFO] [07/12/2017 14:39:01.752] [IotSystem-akka.actor.default-dispatcher-17] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager] IoT Agent -> Received MQTT message: thermostat-1015 | State 2 | Setting 66 [info] [INFO] [07/12/2017 14:39:01.753] [ClusterSystem-akka.actor.default-dispatcher-3] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work for thermostat-1015 : Work Id c57d21af-3957-43ba-a995-f4f558900fa3 [info] [INFO] [07/12/2017 14:39:01.755] [IotSystem-akka.actor.default-dispatcher-15] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Work for thermostat-1015 accepted | Work Id c57d21af-3957-43ba-a995-f4f558900fa3 [info] [INFO] [07/12/2017 14:39:01.757] [ClusterSystem-akka.actor.default-dispatcher-19] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work for thermostat-1015 to Worker 3ec3b314-1c35-4e57-92b3-41c9edb86fbc | Work Id c57d21af-3957-43ba-a995-f4f558900fa3 [info] [INFO] [07/12/2017 14:39:01.758] [WorkerSystem-akka.actor.default-dispatcher-18] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker] Worker -> Received work request from thermostat-1015 | State 2 | Setting 66 [info] [INFO] [07/12/2017 14:39:01.758] [WorkerSystem-akka.actor.default-dispatcher-18] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker/work-processor] Work Processor -> thermostat-1015: Switch to OFF | RAISE temperature by 2 [info] [INFO] [07/12/2017 14:39:01.758] [WorkerSystem-akka.actor.default-dispatcher-18] [akka.tcp://WorkerSystem@127.0.0.1:59399/user/worker] Worker -> Processed work: thermostat-1015 | Work Id c57d21af-3957-43ba-a995-f4f558900fa3 [info] [INFO] [07/12/2017 14:39:01.760] [ClusterSystem-akka.actor.default-dispatcher-25] [akka.tcp://ClusterSystem@127.0.0.1:59407/user/result-processor] Result Processor -> Got work result: thermostat-1015 | State 0 | Setting 68 [info] [INFO] [07/12/2017 14:39:01.761] [ClusterSystem-akka.actor.default-dispatcher-25] [akka.tcp://ClusterSystem@127.0.0.1:59407/user/result-processor] Result Processor -> Sent work result for thermostat-1015 to IoT Manager [info] [INFO] [07/12/2017 14:39:01.761] [IotSystem-akka.actor.default-dispatcher-18] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager] IoT Manager -> Work result forwarded to thermostat-1015 [info] [INFO] [07/12/2017 14:39:01.761] [IotSystem-akka.actor.default-dispatcher-15] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> thermostat-1015 received work result with work Id c57d21af-3957-43ba-a995-f4f558900fa3. [info] [INFO] [07/12/2017 14:39:01.761] [IotSystem-akka.actor.default-dispatcher-15] [akka.tcp://IotSystem@127.0.0.1:3001/user/iot-manager/thermostat-1015] Device -> Updated thermostat-1015 with state 0 and setting 68. .... ....
The following annotated console log showcases fault-tolerance of the master cluster – how it fails over to the 2nd node upon detecting that the 1st node crashes:
# ### Annotated console log from the 2nd cluster node # <<< <<<--- 2nd cluster node (with port# 2552) starts shortly after 1st node (with port# 2551) has started. <<< Leos-MBP:akka-iot-mqtt-v2 leo$ bin/sbt "runMain akkaiot.Main 2552" [info] Loading project definition from /Users/leo/apps/scala/akka-iot-mqtt-v2/project [info] Set current project to akka-iot-mqtt (in build file:/Users/leo/apps/scala/akka-iot-mqtt-v2/) [info] Running akkaiot.Main 2552 [info] [INFO] [07/12/2017 14:24:16.491] [main] [akka.remote.Remoting] Starting remoting [info] [INFO] [07/12/2017 14:24:16.661] [main] [akka.remote.Remoting] Remoting started; listening on addresses :[akka.tcp://ClusterSystem@127.0.0.1:2552] [info] [INFO] [07/12/2017 14:24:16.662] [main] [akka.remote.Remoting] Remoting now listens on addresses: [akka.tcp://ClusterSystem@127.0.0.1:2552] [info] [INFO] [07/12/2017 14:24:16.675] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Starting up... [info] [INFO] [07/12/2017 14:24:16.790] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Registered cluster JMX MBean [akka:type=Cluster] [info] [INFO] [07/12/2017 14:24:16.790] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Started up successfully [info] [INFO] [07/12/2017 14:24:16.794] [ClusterSystem-akka.actor.default-dispatcher-4] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Metrics will be retreived from MBeans, and may be incorrect on some platforms. To increase metric accuracy add the 'sigar.jar' to the classpath and the appropriate platform-specific native libary to 'java.library.path'. Reason: java.lang.ClassNotFoundException: org.hyperic.sigar.Sigar [info] [INFO] [07/12/2017 14:24:16.797] [ClusterSystem-akka.actor.default-dispatcher-4] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Metrics collection has started successfully [info] [WARN] [07/12/2017 14:24:16.822] [ClusterSystem-akka.actor.default-dispatcher-18] [akka.tcp://ClusterSystem@127.0.0.1:2552/system/cluster/core/daemon/downingProvider] Don't use auto-down feature of Akka Cluster in production. See 'Auto-downing (DO NOT USE)' section of Akka Cluster documentation. <<< <<<--- Gets 'welcome' acknowledgement from 1st cluster node. <<< [info] [INFO] [07/12/2017 14:24:17.234] [ClusterSystem-akka.actor.default-dispatcher-4] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Welcome from [akka.tcp://ClusterSystem@127.0.0.1:2551] [info] [INFO] [07/12/2017 14:24:17.697] [ClusterSystem-akka.actor.default-dispatcher-24] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master] ClusterSingletonManager state change [Start -> Younger] <<< <<<--- 1st cluster node crashes after running for about a minute! <<< [info] [WARN] [07/12/2017 14:25:17.329] [ClusterSystem-akka.remote.default-remote-dispatcher-6] [akka.tcp://ClusterSystem@127.0.0.1:2552/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2551-0] Association with remote system [akka.tcp://ClusterSystem@127.0.0.1:2551] has failed, address is now gated for [5000] ms. Reason: [Disassociated] [info] [INFO] [07/12/2017 14:25:17.336] [ClusterSystem-akka.actor.default-dispatcher-24] [akka://ClusterSystem/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2551-0/endpointWriter] Message [akka.remote.EndpointWriter$AckIdleCheckTimer$] from Actor[akka://ClusterSystem/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2551-0/endpointWriter#1930129898] to Actor[akka://ClusterSystem/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2551-0/endpointWriter#1930129898] was not delivered. [1] dead letters encountered. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [info] [INFO] [07/12/2017 14:25:17.828] [ClusterSystem-akka.actor.default-dispatcher-24] [akka://ClusterSystem/deadLetters] Message [akka.cluster.pubsub.DistributedPubSubMediator$Internal$Status] from Actor[akka://ClusterSystem/system/distributedPubSubMediator#-2106783060] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [2] dead letters encountered. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [info] [INFO] [07/12/2017 14:25:18.257] [ClusterSystem-akka.actor.default-dispatcher-24] [akka://ClusterSystem/deadLetters] Message [akka.cluster.ClusterHeartbeatSender$Heartbeat] from Actor[akka://ClusterSystem/system/cluster/core/daemon/heartbeatSender#-975290267] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [3] dead letters encountered. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [info] [INFO] [07/12/2017 14:25:18.826] [ClusterSystem-akka.actor.default-dispatcher-4] [akka://ClusterSystem/deadLetters] Message [akka.cluster.pubsub.DistributedPubSubMediator$Internal$Status] from Actor[akka://ClusterSystem/system/distributedPubSubMediator#-2106783060] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [4] dead letters encountered. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. .... .... [info] [WARN] [07/12/2017 14:25:20.828] [ClusterSystem-akka.actor.default-dispatcher-4] [akka.tcp://ClusterSystem@127.0.0.1:2552/system/cluster/core/daemon] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Marking node(s) as UNREACHABLE [Member(address = akka.tcp://ClusterSystem@127.0.0.1:2551, status = Up)]. Node roles [backend] [info] [INFO] [07/12/2017 14:25:21.258] [ClusterSystem-akka.actor.default-dispatcher-20] [akka://ClusterSystem/deadLetters] Message [akka.cluster.ClusterHeartbeatSender$Heartbeat] from Actor[akka://ClusterSystem/system/cluster/core/daemon/heartbeatSender#-975290267] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [9] dead letters encountered. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [info] [INFO] [07/12/2017 14:25:21.827] [ClusterSystem-akka.actor.default-dispatcher-24] [akka://ClusterSystem/deadLetters] Message [akka.cluster.pubsub.DistributedPubSubMediator$Internal$Status] from Actor[akka://ClusterSystem/system/distributedPubSubMediator#-2106783060] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [10] dead letters encountered, no more dead letters will be logged. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [info] [WARN] [07/12/2017 14:25:23.260] [New I/O boss #3] [NettyTransport(akka://ClusterSystem)] Remote connection to null failed with java.net.ConnectException: Connection refused: /127.0.0.1:2551 [info] [WARN] [07/12/2017 14:25:23.262] [ClusterSystem-akka.remote.default-remote-dispatcher-6] [akka.tcp://ClusterSystem@127.0.0.1:2552/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2551-0] Association with remote system [akka.tcp://ClusterSystem@127.0.0.1:2551] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://ClusterSystem@127.0.0.1:2551]] Caused by: [Connection refused: /127.0.0.1:2551] [info] [WARN] [07/12/2017 14:25:28.829] [New I/O boss #3] [NettyTransport(akka://ClusterSystem)] Remote connection to null failed with java.net.ConnectException: Connection refused: /127.0.0.1:2551 [info] [WARN] [07/12/2017 14:25:28.830] [ClusterSystem-akka.remote.default-remote-dispatcher-5] [akka.tcp://ClusterSystem@127.0.0.1:2552/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2551-0] Association with remote system [akka.tcp://ClusterSystem@127.0.0.1:2551] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://ClusterSystem@127.0.0.1:2551]] Caused by: [Connection refused: /127.0.0.1:2551] [info] [INFO] [07/12/2017 14:25:30.845] [ClusterSystem-akka.actor.default-dispatcher-4] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Leader is auto-downing unreachable node [akka.tcp://ClusterSystem@127.0.0.1:2551]. Don't use auto-down feature of Akka Cluster in production. See 'Auto-downing (DO NOT USE)' section of Akka Cluster documentation. [info] [INFO] [07/12/2017 14:25:30.846] [ClusterSystem-akka.actor.default-dispatcher-21] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Marking unreachable node [akka.tcp://ClusterSystem@127.0.0.1:2551] as [Down] <<< <<<--- 1st cluster node (with port# 2551) is marked as 'down'. <<< [info] [INFO] [07/12/2017 14:25:31.830] [ClusterSystem-akka.actor.default-dispatcher-21] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] - Leader is removing unreachable node [akka.tcp://ClusterSystem@127.0.0.1:2551] [info] [INFO] [07/12/2017 14:25:31.832] [ClusterSystem-akka.actor.default-dispatcher-19] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master] Previous oldest removed [akka.tcp://ClusterSystem@127.0.0.1:2551] <<< <<<--- 2nd cluster node (with port# 2552) replaces 1st node to start a new master singleton actor. <<< [info] [INFO] [07/12/2017 14:25:31.833] [ClusterSystem-akka.actor.default-dispatcher-24] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master] Younger observed OldestChanged: [None -> myself] [info] [WARN] [07/12/2017 14:25:31.833] [ClusterSystem-akka.remote.default-remote-dispatcher-15] [akka.remote.Remoting] Association to [akka.tcp://ClusterSystem@127.0.0.1:2551] having UID [1664659180] is irrecoverably failed. UID is now quarantined and all messages to this UID will be delivered to dead letters. Remote actorsystem must be restarted to recover from this situation. [info] [INFO] [07/12/2017 14:25:31.877] [ClusterSystem-akka.actor.default-dispatcher-24] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master] Singleton manager starting singleton actor [akka://ClusterSystem/user/master/singleton] [info] [INFO] [07/12/2017 14:25:31.878] [ClusterSystem-akka.actor.default-dispatcher-24] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master] ClusterSingletonManager state change [Younger -> Oldest] [info] [INFO] [07/12/2017 14:25:31.994] [ClusterSystem-rediscala.rediscala-client-worker-dispatcher-28] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/RedisClient-$a] Connect to localhost/127.0.0.1:6379 [info] [INFO] [07/12/2017 14:25:32.015] [ClusterSystem-rediscala.rediscala-client-worker-dispatcher-28] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/RedisClient-$a] Connected to localhost/127.0.0.1:6379 [info] [INFO] [07/12/2017 14:25:32.093] [ClusterSystem-rediscala.rediscala-client-worker-dispatcher-28] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/RedisClient-$b] Connect to localhost/127.0.0.1:6379 [info] [INFO] [07/12/2017 14:25:32.095] [ClusterSystem-rediscala.rediscala-client-worker-dispatcher-28] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/RedisClient-$b] Connected to localhost/127.0.0.1:6379 <<< <<<--- The new master singleton actor starts replaying events stored in the persistence journal. <<< [info] [INFO] [07/12/2017 14:25:32.485] [ClusterSystem-akka.actor.default-dispatcher-16] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Replayed event: WorkAccepted [info] [INFO] [07/12/2017 14:25:32.486] [ClusterSystem-akka.actor.default-dispatcher-16] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Replayed event: WorkAccepted [info] [INFO] [07/12/2017 14:25:32.486] [ClusterSystem-akka.actor.default-dispatcher-16] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Replayed event: WorkAccepted .... .... [info] [INFO] [07/12/2017 14:25:32.532] [ClusterSystem-akka.actor.default-dispatcher-3] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Replayed event: WorkStarted [info] [INFO] [07/12/2017 14:25:32.532] [ClusterSystem-akka.actor.default-dispatcher-3] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Replayed event: WorkCompleted [info] [INFO] [07/12/2017 14:25:32.533] [ClusterSystem-akka.actor.default-dispatcher-3] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Replayed event: WorkAccepted [info] [INFO] [07/12/2017 14:25:32.533] [ClusterSystem-akka.actor.default-dispatcher-3] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Replayed event: WorkStarted [info] [INFO] [07/12/2017 14:25:32.533] [ClusterSystem-akka.actor.default-dispatcher-3] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Replayed event: WorkCompleted <<< <<<--- The new master singleton actor starts resuming live operation <<< [info] [INFO] [07/12/2017 14:25:32.863] [ClusterSystem-akka.actor.default-dispatcher-40] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for security-alarm-1013 : Work Id f2a1e777-1e35-4b79-9acb-87477358adc1 [info] [WARN] [SECURITY][07/12/2017 14:25:32.874] [ClusterSystem-akka.persistence.dispatchers.default-plugin-dispatcher-26] [akka.serialization.Serialization(akka://ClusterSystem)] Using the default Java serializer for class [akkaiot.WorkQueue$WorkAccepted] which is not recommended because of performance implications. Use another serializer or disable this warning using the setting 'akka.actor.warn-about-java-serializer-usage' [info] [WARN] [SECURITY][07/12/2017 14:25:32.908] [ClusterSystem-akka.remote.default-remote-dispatcher-5] [akka.serialization.Serialization(akka://ClusterSystem)] Using the default Java serializer for class [akkaiot.Master$Ack] which is not recommended because of performance implications. Use another serializer or disable this warning using the setting 'akka.actor.warn-about-java-serializer-usage' [info] [INFO] [07/12/2017 14:25:33.694] [ClusterSystem-akka.actor.default-dispatcher-40] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for security-alarm-1001 : Work Id cfe1ecb3-683d-46f4-ab7e-d8c66fa88755 [info] [INFO] [07/12/2017 14:25:33.851] [ClusterSystem-akka.actor.default-dispatcher-16] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for lamp-1002 : Work Id 469f7148-a6f8-43e6-aa2e-764ac911c251 [info] [INFO] [07/12/2017 14:25:34.014] [ClusterSystem-akka.actor.default-dispatcher-16] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for thermostat-1015 : Work Id 92cb01ea-bb90-482c-b20b-accd4770f21a [info] [INFO] [07/12/2017 14:25:34.172] [ClusterSystem-akka.actor.default-dispatcher-16] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for thermostat-1005 : Work Id 73ccc2c1-ceb7-4923-b705-8fe82c666bc5 [info] [INFO] [07/12/2017 14:25:34.614] [ClusterSystem-akka.actor.default-dispatcher-16] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for thermostat-1012 : Work Id 711b212c-c53d-4f41-a9fa-e8f5ad44ad55 [info] [INFO] [07/12/2017 14:25:35.040] [ClusterSystem-akka.actor.default-dispatcher-22] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for lamp-1009 : Work Id 435264de-5891-4ee9-a7f8-352f7c0abc11 [info] [INFO] [07/12/2017 14:25:35.533] [ClusterSystem-akka.actor.default-dispatcher-22] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for thermostat-1008 : Work Id 2873a66e-b04f-40d0-be49-0500449f54f4 [info] [INFO] [07/12/2017 14:25:35.692] [ClusterSystem-akka.actor.default-dispatcher-22] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for thermostat-1020 : Work Id eefc57d2-8571-4820-8a6e-a7b083fdbaca [info] [INFO] [07/12/2017 14:25:35.849] [ClusterSystem-akka.actor.default-dispatcher-37] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for lamp-1007 : Work Id bdcb4f22-4ca9-4b76-9f43-68a1168637cf [info] [INFO] [07/12/2017 14:25:36.009] [ClusterSystem-akka.actor.default-dispatcher-37] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for security-alarm-1006 : Work Id 01999269-3608-4877-85ef-6c75f39f7db9 [info] [INFO] [07/12/2017 14:25:37.024] [ClusterSystem-akka.actor.default-dispatcher-37] [akka.tcp://ClusterSystem@127.0.0.1:2552/user/master/singleton] Cluster Master -> Accepted work for thermostat-1004 : Work Id ccbc9edb-7a60-4f65-8121-261928f01ff2 .... ....
Scaling for production
The Actor model is well suited for building scalable distributed systems. While the application has an underlying architecture that emphasizes on scalability, it would require further effort in the following areas to make it production ready:
- IotManager uses the ‘ask’ method for message receipt confirmation via a Future return by the Master. If business logic allows, using the fire-and-forget ‘tell’ method will be significantly more efficient especially at scale.
- The MQTT broker used in the application is a test broker provided by Mosquitto. A production version of the broker should be installed preferably local to the the IoT system. MQTT brokers from other vendors like HiveMQ, RabbitMQ are also available.
- As displayed in the console log when running the application, Akka’s default Java serializer isn’t best known for its efficiency. Other serializers such as Kryo, Protocol Buffers should be considered.
- The Redis data store for actor state persistence should be configured for production environment
Further code changes to be considered
A couple of changes to the current application might be worth considering:
Device types are currently represented as strings, and code logic for device type-specific states and settings is repeated during instantiation of devices and processing of work requests. Such logic could be encapsulated within classes defined for individual device types. The payload would probably be larger as a consequence, but it might be worth for better code maintainability especially if there are many device types.
Another change to be considered is that Work and WorkResult could be generalized into a single class. Conversely, they could be further differentiated in accordance with specific business needs. A slightly more extensive change would be to retire ResultProcessor altogether and let Worker actors process WorkResult as well.
State mutation in Akka Actors
In this application, a few actors maintain mutable internal states using private variables (private var):
- Master
- IotManager
- Device
As an actor by-design will never be accessed by multiple threads, it’s generally safe enough to use ‘private var’ to store changed states. But if one prefers state transitioning (as opposed to updating), Akka Actors provides a method to hot-swap an actor’s internal state.
Hot-swapping an actor’s state
Below is a sample snippet that illustrates how hot-swapping mimics a state machine without having to use any mutable variable for maintaining the actor state:
// An Actor that mutates internal state by hot-swapping
object Worker {
def props(workerId, String, clusterClient: ActorRef) = // ...
// ...
}
class Worker(workerId, String, clusterClient: ActorRef) extends Actor {
import Worker._
override def preStart(): Unit = // Initialize worker
override def postStop(): Unit = // Terminate worker
def sendToMaster(msg: Any): Unit = {
clusterClient ! SendToAll("/user/master/singleton", msg)
}
// ...
def receive = idle
def idle: Receive = {
case WorkIsReady =>
// Tell Master it is free
sendToMaster(WorkerIsFree(workerId))
case Work =>
// Send work to a work processing actor
workProcessor ! work
context.become(working)
}
def working: Receive = {
case WorkProcessed(workResult) =>
// Tell Master work is done
sendToMaster(WorkIsDone(workerId, workResult))
context.become(idle)
case Work =>
// Tell Master it is busy
sendToMaster(WorkerIsBusy(workerId))
}
}
Simplified for illustration, the above snippet depicts a Worker actor that pulls work from the Master cluster. The context.become method allows the actor to switch its internal state at run-time like a state machine. As shown in the simplified code, it takes an ‘Actor.Receive’ (which is a partial function) that implements a new message handler. Under the hood, Akka manages the hot-swapping via a stack. As a side note, according to the relevant source code, the stack for hot-swapping actor behavior is, ironically, a mutable ‘private var’ of List[Actor.Receive].
Recursive transformation of immutable parameter
Another functional approach to mutating actor state is via recursive transformation of an immutable parameter. As an example, we can avoid using a mutable ‘private var registry’ as shown in the following ActorManager actor and use ‘context.become’ to recursively transform a registry as an immutable parameter passed to the updateState method:
// Approach #1: Store map entries in a mutable registry
class ActorManager extends Actor {
private var registry: Map.empty[String, ActorRef]
def receive = {
case Add(id, ref) =>
registry += id -> ref
// Other cases
}
}
// Approach #2: Store map entries in a recursively transformed immutable registry
class ActorManager extends Actor {
def receive = updateRegistry(Map.empty[String, ActorRef])
def updateState(registry: Map[String, ActorRef]): Receive = {
case Add(id, ref) =>
context.become(updateState(registry + (id -> ref)))
// Other cases
}
}