
In a previous startup I cofounded, our core product was a geospatial application that provided algorithmic ratings of the individual residential real estate properties for home buyers. Given that there were over 100+ millions of residential properties nationwide, the collective data volume of all the associated attributes necessary for the data engineering work was massive.
For the initial MVP (minimum viable product) releases in which we only needed to showcase our product features in a selected metropolitan area, we used PostgreSQL as the OLTP (online transaction processing) database. Leveraging Postgres’ table partitioning feature, we had an OLTP database capable of accommodating incremental geographical expansion into multiple cities and states.
Batch ETL
The need for a big data warehouse wasn’t imminent in the beginning, though we had to make sure a data processing platform for a highly scalable data warehouse along with efficient ETL (extract/transform/load) functions would be ready on a short notice. The main objective was to make sure the OLTP database could be kept at a minimal volume while less frequently used data got “archived” off to a big data warehouse for data analytics.
With limited engineering resources available in a small startup, I kicked off a R&D project on the side to build programmatic ETL processes to periodically funnel data from PostgreSQL to a big data warehouse in a batch manner. Cassandra was chosen to be the data warehouse and was configured on an Amazon EC2 cluster. The project was finished with a batch ETL solution that functionally worked as intended, although back in my mind a more “continuous” operational model would be preferred.
Real-time Streaming ETL
Fast-forward to 2021, I recently took on a big data streaming project that involves ETL and building data pipelines on a distributed platform. Central to the project requirement is real-time (or more precisely, near real-time) processing of high-volume data. Another aspect of the requirement is that the streaming system has to accommodate custom data pipelines as composable components of the consumers, suggesting that a streaming ETL solution would be more suitable than a batch one. Lastly, stream consumption needs to guarantee at-least-once delivery.
Given all that, Apache Kafka promptly stood out as a top candidate to serve as the distributed streaming brokers. In particular, its capability of keeping durable data in a distributed fault-tolerant cluster allows it to serve different consumers at various instances of time and locales. Next, Akka Stream was added to the tech stack for its versatile stream-based application integration functionality as well as benefits of reactive streams.
Alpakka – a reactive stream API and DSL
Built on top of Akka Stream, Alpakka provides a comprehensive API and DSL (domain specific language) for reactive and stream-oriented programming to address the application integration needs for interoperating with a wide range of prominent systems across various computing domains. That, coupled with the underlying Akka Stream’s versatile streaming functions, makes Alpakka a powerful toolkit for what is needed.
In this blog post, we’ll assemble in Scala a producer and a consumer using the Alpakka API to perform streaming ETL from a PostgreSQL database through Kafka brokers into a Cassandra data warehouse. In a subsequent post, we’ll enhance and package up these snippets to address the requirement of at-least-once delivery in consumption and composability of data pipelines.
Streaming ETL with Alpakka Kafka, Slick, Cassandra, …
The following diagram shows the near-real time ETL functional flow of data streaming from various kinds of data sources (e.g. a PostgreSQL database or a CSV file) to data destinations (e.g. a Cassandra data warehouse or a custom data stream outlet).
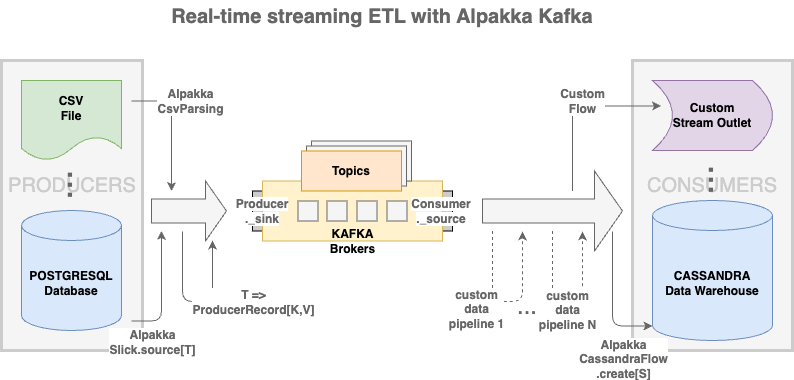
The Apache Kafka brokers provide a distributed publish-subscribe platform for keeping in-flight data in durable immutable logs readily available for consumption. Meanwhile, the Akka Stream based Alpakka API that comes with a DSL allows programmatic integrations to compose data pipelines as sources, sinks and flows, in addition to enabling “reactivity” by equipping the streams with non-blocking backpressure.
It should be noted that the same stream can be processed using various data sources and destinations simultaneously. For instance, data with the same schema from both the CSV file and Postgres database could be published to the same topic and consumed by a consumer group designated for the Cassandra database and another consumer group for a different data storage.
Example: ETL of real estate property listing data
The platform will be for general-purpose ETL/pipelining. For illustration purpose in this blog post, we’re going to use it to perform streaming ETL of some simplified dataset of residential real estate property listings.
First, we create a simple class to represent a property listing.
package alpakkafka
case class PropertyListing(
propertyId: Int,
dataSource: Option[String],
bathrooms: Option[Double],
bedrooms: Option[Int],
listPrice: Option[Double],
livingArea: Option[Int],
propertyType: Option[String],
yearBuilt: Option[String],
lastUpdated: Option[String],
streetAddress: Option[String],
city: Option[String],
state: Option[String],
zip: Option[String],
country: Option[String]
) {
def summary(): String = {
val ba = bathrooms.getOrElse(0)
val br = bedrooms.getOrElse(0)
val price = listPrice.getOrElse(0)
val area = livingArea.getOrElse(0)
val street = streetAddress.getOrElse("")
val cit = city.getOrElse("")
val sta = state.getOrElse("")
s"PropertyID: $propertyId | Price: $$$price ${br}BR/${ba}BA/${area}sqft | Address: $street, $cit, $sta"
}
}
Using the good old sbt as the build tool, relevant library dependencies for Akka Stream, Alpakka Kafka, Postgres/Slick and Cassandra/DataStax are included in build.sbt.
name := "alpakka-streaming-etl" version := "0.1" scalaVersion := "2.13.6" scalacOptions += "-deprecation" val akkaVersion = "2.6.16" libraryDependencies ++= Seq( "com.typesafe.akka" %% "akka-actor" % akkaVersion, "com.typesafe.akka" %% "akka-slf4j" % akkaVersion, "com.typesafe.akka" %% "akka-stream" % akkaVersion, "com.typesafe.akka" %% "akka-stream-kafka" % "2.1.1", "com.lightbend.akka" %% "akka-stream-alpakka-slick" % "3.0.3", "org.postgresql" % "postgresql" % "42.2.24", "com.lightbend.akka" %% "akka-stream-alpakka-csv" % "3.0.3", "com.lightbend.akka" %% "akka-stream-alpakka-cassandra" % "3.0.3", "com.datastax.oss" % "java-driver-core" % "4.13.0", "org.apache.tinkerpop" % "tinkergraph-gremlin" % "3.5.1", "io.spray" %% "spray-json" % "1.3.6", "ch.qos.logback" % "logback-classic" % "1.2.4" % Runtime ) trapExit := false
Next, we put configurations for Akka Actor, Alpakka Kafka, Slick and Cassandra in application.conf under src/main/resources/:
akka {
loggers = ["akka.event.slf4j.Slf4jLogger"]
logging-filter = "akka.event.slf4j.Slf4jLoggingFilter"
}
akka.actor.allow-java-serialization = on
slick-postgres {
profile = "slick.jdbc.PostgresProfile$"
db {
dataSourceClass = "slick.jdbc.DriverDataSource"
properties = {
driver = "org.postgresql.Driver"
url = "jdbc:postgresql://localhost/propertydb"
user = "pipeliner"
password = "pa$$word"
}
}
}
akka.kafka.producer {
discovery-method = akka.discovery
service-name = ""
resolve-timeout = 3 seconds
parallelism = 10000
close-timeout = 60s
close-on-producer-stop = true
use-dispatcher = "akka.kafka.default-dispatcher"
eos-commit-interval = 100ms
kafka-clients {
}
}
akkafka.producer.with-brokers: ${akka.kafka.producer} {
kafka-clients {
bootstrap.servers = "127.0.0.1:9092"
}
}
akka.kafka.consumer {
poll-interval = 250ms # 50ms
poll-timeout = 50ms
stop-timeout = 10s # 30s
close-timeout = 10s # 20s
commit-timeout = 10s # 15s
wakeup-timeout = 10s
eos-draining-check-interval = 30ms
use-dispatcher = "akka.kafka.default-dispatcher"
kafka-clients {
enable.auto.commit = true # `true` for `Consumer.plainSource`
}
}
akkafka.consumer.with-brokers: ${akka.kafka.consumer} {
kafka-clients {
bootstrap.servers = "127.0.0.1:9092"
}
}
akka.kafka.committer {
max-batch = 1000
max-interval = 10s
parallelism = 100
delivery = WaitForAck
when = OffsetFirstObserved
}
alpakka.cassandra {
session-provider = "akka.stream.alpakka.cassandra.DefaultSessionProvider"
service-discovery {
name = ""
lookup-timeout = 1 s
}
session-dispatcher = "akka.actor.default-dispatcher"
datastax-java-driver-config = "datastax-java-driver"
}
datastax-java-driver {
basic {
contact-points = ["127.0.0.1:9042"]
load-balancing-policy.local-datacenter = datacenter1
}
advanced.reconnect-on-init = true
}
Note that the sample configuration is for running the application with all Kafka, PostgreSQL and Cassandra on a single computer. The host IPs (i.e. 127.0.0.1) should be replaced with their corresponding host IPs/names in case they’re on separate hosts. For example, relevant configurations for Kafka brokers and Cassandra database spanning across multiple hosts might look something like bootstrap.servers = "10.1.0.1:9092,10.1.0.2:9092,10.1.0.3:9092" and contact-points = ["10.2.0.1:9042","10.2.0.2:9042"].
PostgresProducerPlain – an Alpakka Kafka producer
The PostgresProducerPlain snippet below creates a Kafka producer using Alpakka Slick which allows SQL queries to be coded in Slick’s functional programming style.
package alpakkafka
import akka.actor.ActorSystem
import akka.stream.scaladsl._
import akka.{Done, NotUsed}
import akka.stream.alpakka.slick.scaladsl._
import akka.kafka.ProducerSettings
import akka.kafka.scaladsl.Producer
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.serialization.StringSerializer
import spray.json._
import spray.json.DefaultJsonProtocol._
import scala.concurrent.{ExecutionContext, Future}
import scala.util.Try
object PostgresProducerPlain {
def run(topic: String,
offset: Int = 0,
limit: Int = Int.MaxValue)(implicit
slickSession: SlickSession,
jsonFormat: JsonFormat[PropertyListing],
system: ActorSystem,
ec: ExecutionContext): Future[Done] = {
import slickSession.profile.api._
class PropertyListings(tag: Tag) extends Table[PropertyListing](tag, "property_listing") {
def propertyId = column[Int]("property_id", O.PrimaryKey)
def dataSource = column[Option[String]]("data_source")
def bathrooms = column[Option[Double]]("bathrooms")
def bedrooms = column[Option[Int]]("bedrooms")
def listPrice = column[Option[Double]]("list_price")
def livingArea = column[Option[Int]]("living_area")
def propertyType = column[Option[String]]("property_type")
def yearBuilt = column[Option[String]]("year_built")
def lastUpdated = column[Option[String]]("last_updated")
def streetAddress = column[Option[String]]("street_address")
def city = column[Option[String]]("city")
def state = column[Option[String]]("state")
def zip = column[Option[String]]("zip")
def country = column[Option[String]]("country")
def * =
(propertyId, dataSource, bathrooms, bedrooms, listPrice, livingArea, propertyType, yearBuilt, lastUpdated, streetAddress, city, state, zip, country) <> (PropertyListing.tupled, PropertyListing.unapply)
}
val source: Source[PropertyListing, NotUsed] =
Slick
.source(TableQuery[PropertyListings].sortBy(_.propertyId).drop(offset).take(limit).result)
val producerConfig = system.settings.config.getConfig("akkafka.producer.with-brokers")
val producerSettings =
ProducerSettings(producerConfig, new StringSerializer, new StringSerializer)
source
.map{ property =>
val prodRec = new ProducerRecord[String, String](
topic, property.propertyId.toString, property.toJson.compactPrint
)
println(s"[POSTRES] >>> Producer msg: $prodRec")
prodRec
}
.runWith(Producer.plainSink(producerSettings))
}
def main(args: Array[String]): Unit = {
implicit val system = ActorSystem()
implicit val ec = system.dispatcher
implicit val propertyListingJsonFormat: JsonFormat[PropertyListing] = jsonFormat14(PropertyListing)
implicit val slickSession = SlickSession.forConfig("slick-postgres")
val topic = "property-listing-topic"
val offset: Int = if (args.length >= 1) Try(args(0).toInt).getOrElse(0) else 0
val limit: Int = if (args.length == 2) Try(args(1).toInt).getOrElse(Int.MaxValue) else Int.MaxValue
run(topic, offset, limit) onComplete{ _ =>
slickSession.close()
system.terminate()
}
}
}
Method Slick.source[T]() takes a streaming query and returns a Source[T, NotUsed]. In this case, T is PropertyListing. Note that Slick.source() can also take a plain SQL statement wrapped within sql"..." as its argument, if wanted (in which case an implicit value of slick.jdbc.GetResult should be defined).
A subsequent map wraps each of the property listing objects in a ProducerRecord[K,V] with topic and key/value of type String/JSON, before publishing to the Kafka topic via Alpakka Kafka’s Producer.plainSink[K,V].
To run PostgresProducerPlain, simply navigate to the project root and execute the following command from within a command line terminal:
# sbt "runMain alpakkafka.PostgresProducerPlain" # Stream the first 20 rows from property_listing in Postgres into Kafka under topic "property-listing" sbt "runMain alpakkafka.PostgresProducerPlain 0 20" # Stream all rows from property_listing in Postgres into Kafka under topic "property-listing" sbt "runMain alpakkafka.PostgresProducerPlain"
CassandraConsumerPlain – an Alpakka Kafka consumer
Using Alpakka Kafka, CassandraConsumerPlain shows how a basic Kafka consumer can be formulated as an Akka stream that consumes data from Kafka via Consumer.plainSource followed by a stream processing operator, Alpakka Cassandra’s CassandraFlow to stream the data into a Cassandra database.
package alpakkafka
import akka.actor.ActorSystem
import akka.stream.scaladsl._
import akka.{Done, NotUsed}
import akka.kafka.{CommitterSettings, ConsumerSettings, Subscriptions}
import akka.kafka.scaladsl.{Committer, Consumer}
import akka.kafka.scaladsl.Consumer.DrainingControl
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import akka.stream.alpakka.cassandra.{CassandraSessionSettings, CassandraWriteSettings}
import akka.stream.alpakka.cassandra.scaladsl.{CassandraSession, CassandraSessionRegistry}
import akka.stream.alpakka.cassandra.scaladsl.{CassandraFlow, CassandraSource}
import com.datastax.oss.driver.api.core.cql.{BoundStatement, PreparedStatement}
import spray.json._
import spray.json.DefaultJsonProtocol._
import scala.concurrent.{ExecutionContext, Future}
import java.util.concurrent.atomic.AtomicReference
import scala.util.{Failure, Success, Try}
object CassandraConsumerPlain {
def run(consumerGroup: String,
topic: String)(implicit
cassandraSession: CassandraSession,
jsonFormat: JsonFormat[PropertyListing],
system: ActorSystem,
ec: ExecutionContext): Future[Done] = {
val consumerConfig = system.settings.config.getConfig("akkafka.consumer.with-brokers")
val consumerSettings =
ConsumerSettings(consumerConfig, new StringDeserializer, new StringDeserializer)
.withGroupId(consumerGroup)
.withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
val table = "propertydata.property_listing"
val partitions = 10 // number of partitions
val statementBinder: (ConsumerRecord[String, String], PreparedStatement) => BoundStatement = {
case (msg, preparedStatement) =>
val p = msg.value().parseJson.convertTo[PropertyListing]
preparedStatement.bind(
(p.propertyId % partitions).toString, Int.box(p.propertyId), p.dataSource.getOrElse("unknown"),
Double.box(p.bathrooms.getOrElse(0)), Int.box(p.bedrooms.getOrElse(0)), Double.box(p.listPrice.getOrElse(0)), Int.box(p.livingArea.getOrElse(0)),
p.propertyType.getOrElse(""), p.yearBuilt.getOrElse(""), p.lastUpdated.getOrElse(""), p.streetAddress.getOrElse(""), p.city.getOrElse(""), p.state.getOrElse(""), p.zip.getOrElse(""), p.country.getOrElse("")
)
}
val cassandraFlow: Flow[ConsumerRecord[String, String], ConsumerRecord[String, String], NotUsed] =
CassandraFlow.create(
CassandraWriteSettings.defaults,
s"""INSERT INTO $table (partition_key, property_id, data_source, bathrooms, bedrooms, list_price, living_area, property_type, year_built, last_updated, street_address, city, state, zip, country)
|VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)""".stripMargin,
statementBinder
)
val control: DrainingControl[Done] =
Consumer
.plainSource(consumerSettings, Subscriptions.topics(topic))
.via(cassandraFlow)
.toMat(Sink.ignore)(DrainingControl.apply)
.run()
Thread.sleep(5000)
control.drainAndShutdown()
}
def query(sql: String)(implicit
cassandraSession: CassandraSession,
system: ActorSystem,
ec: ExecutionContext): Future[Seq[(String, PropertyListing)]] = {
CassandraSource(sql)
.map{ r =>
val partitionKey = r.getString("partition_key")
val propertyListingTuple = (
r.getInt("property_id"),
Option(r.getString("data_source")),
Option(r.getDouble("list_price")),
Option(r.getInt("bedrooms")),
Option(r.getDouble("bathrooms")),
Option(r.getInt("living_area")),
Option(r.getString("property_type")),
Option(r.getString("year_built")),
Option(r.getString("last_updated")),
Option(r.getString("street_address")),
Option(r.getString("city")),
Option(r.getString("state")),
Option(r.getString("zip")),
Option(r.getString("country"))
)
val propertyListing = PropertyListing.tupled(propertyListingTuple)
(partitionKey, propertyListing)
}
.runWith(Sink.seq)
}
def main(args: Array[String]): Unit = {
implicit val system = ActorSystem()
implicit val ec = system.dispatcher
implicit val propertyListingJsonFormat: JsonFormat[PropertyListing] = jsonFormat14(PropertyListing)
implicit val cassandraSession: CassandraSession =
CassandraSessionRegistry.get(system).sessionFor(CassandraSessionSettings())
val consumerGroup = "datawarehouse-consumer-group"
val topic = "property-listing-topic"
run(consumerGroup, topic) onComplete(println)
// Query for property listings within a Cassandra partition
val sql = s"SELECT * FROM propertydata.property_listing WHERE partition_key = '0';"
query(sql) onComplete {
case Success(res) => res.foreach(println)
case Failure(e) => println(s"ERROR: $e")
}
Thread.sleep(5000)
system.terminate()
}
}
A few notes:
- Consumer.plainSource: As a first stab at building a consumer, we use Alpakka Kafka’s Consumer.plainSource[K,V] as the stream source. To ensure the stream to be stopped in a controlled fashion, Consumer.Drainingcontrol is included when composing the stream graph. While it’s straight forward to use,
plainSourcedoesn’t offer programmatic tracking of the commit offset position thus cannot guarantee at-least-once delivery. An enhanced version of the consumer will be constructed in a subsequent blog post. - Partition key: Cassandra mandates having a partition key as part of the primary key of every table for distributing across cluster nodes. In our property listing data, we make the modulo of the Postgres primary key
property_idby the number of partitions to be the partition key. It could certainly be redefined to something else (e.g. locale or type of the property) in accordance with the specific business requirement. - CassandraSource: Method
query()simply executes queries against a Cassandra database using CassandraSource which takes a CQL query with syntax similar to standard SQL’s. It isn’t part of the consumer flow, but is rather as a convenient tool for verifying stream consumption result. - CassandraFlow: Alpakka’s CassandraFlow.create[S]() is the main processing operator responsible for streaming data into the Cassandra database. It takes a CQL
PreparedStatementand a “statement binder” that binds the incoming class variables to the corresponding Cassandra columns before executing the insert/update. In this case,SisConsumerRecord[K,V].
To run CassandraConsumerPlain, Navigate to the project root and execute the following from within a command line terminal:
# Stream any uncommitted data from Kafka topic "property-listing" into Cassandra sbt "runMain alpakkafka.CassandraConsumerPlain"
Table schema in PostgreSQL & Cassandra
Obviously, the streaming ETL application is supposed to run in the presence of one or more Kafka brokers, a PostgreSQL database and a Cassandra data warehouse. For proof of concept, getting all these systems with basic configurations on a descent computer (Linux, Mac OS, etc) is a trivial exercise. The ETL application is readily scalable that it would require only configurative changes when, say, needs rise for scaling up of Kafka and Cassandra to span clusters of nodes in the cloud.
Below is how the table schema of property_listing can be created in PostgreSQL via psql:
CREATE ROLE pipeliner WITH createdb login ENCRYPTED PASSWORD 'pa$$word';
CREATE DATABASE propertydb WITH OWNER 'pipeliner' ENCODING 'utf8';
CREATE TABLE property_listing (
property_id integer PRIMARY KEY,
bathrooms numeric,
bedrooms integer,
list_price double precision,
living_area integer,
property_type text,
year_built text,
data_source text,
last_updated timestamp with time zone,
street_address character varying(250),
city character varying(50),
state character varying(50),
zip character varying(10),
country character varying(3)
);
ALTER TABLE property_listing OWNER TO pipeliner;
To create keyspace propertydata and the corresponding table property_listing in Cassandra, one can launch cqlsh and execute the following CQL statements:
CREATE KEYSPACE propertydata
WITH REPLICATION = {
'class' : 'SimpleStrategy', // use 'NetworkTopologyStrategy' for multi-node
'replication_factor' : 2 // use 'datacenter1' for multi-node
};
CREATE TABLE propertydata.property_listing (
partition_key text,
property_id int,
data_source text,
bathrooms double,
bedrooms int,
list_price double,
living_area int,
property_type text,
year_built text,
last_updated text,
street_address text,
city text,
state text,
zip text,
country text,
PRIMARY KEY ((partition_key), property_id)
);
What’s next?
So, we now have a basic streaming ETL system running Alphakka Kafka on top of a cluster of Kafka brokers to form the reactive stream “backbone” for near real-time ETL between data stores. With Alpakka Slick and Alpakka Cassandra, a relational database like PostgreSQL and a Cassandra data warehouse can be made part of the system like composable stream components.
As noted earlier, the existing Cassandra consumer does not guarantee at-least-once delivery, which is part of the requirement. In the next blog post, we’ll enhance the existing consumer to address the required delivery guarantee. We’ll also add a data processing pipeline to illustrate how to construct additional data pipelines as composable stream operators. All relevant source code along with some sample dataset will be published in a GitHub repo.