
IoT (Internet of Things) has recently been one of the most popular buzzwords. Despite being over-hyped, we’re indeed heading towards a foreseeable world in which all sorts of things are inter-connected. Before IoT became a hot acronym, I was heavily involved in building a Home-Area-Network SaaS platform over the course of 5 years in a previous startup I cofounded, so it’s no stranger to me.
At the low-level device network layer, there used to be platform service companies providing gateway hardware along with proprietary APIs for IoT devices running on sensor network protocols (such as ZigBee, Z-Wave). The landscape has been evolving over the past couple of years. As more and more companies begin to throw their weight behind building products in the IoT ecosystem, open standards for device connectivity emerge. One of them is MQTT (Message Queue Telemetry Transport).
Message Queue Telemetry Transport
MQTT had been relatively little-known until it was standardized at OASIS a couple of years ago. The lightweight publish-subscribe messaging protocol, MQTT, has since been increasingly adopted by major players, including Amazon, as the underlying connectivity protocols for IoT devices. It’s TCP/IP based but its variant, MQTT-SN (MQTT for Sensor Networks), covers sensor network communication protocols such as ZigBee. There are also quite a few MQTT message brokers, including HiveMQ, Mosquitto and RabbitMQ.
IoT makes a great use case for Akka actor systems which come with lightweight loosely-coupled actors in decentralized clusters with robust routing, sharding and pub-sub features, as mentioned in a previous blog post. The actor model can be rather easily structured to emulate the operations of a typical IoT network that scales in device volume. In addition, availability of MQTT clients for Akka such as Paho-Akka makes it easy to communicate with MQTT brokers.
A Scala-based IoT application
UPDATE: An expanded version of this application with individual actors representing each of the IoT devices, each of which maintains its own internal state and setting, is now available. Please see the Akka Actors IoT v.2 blog post for details.
In this blog post, I’m going to illustrate how to build a scalable distributed worker system using Akka actors to service requests from a MQTT-based IoT system. A good portion of the Akka clustering setup is derived from Lightbend’s Akka distributed workers template. Below is a diagram of the application:
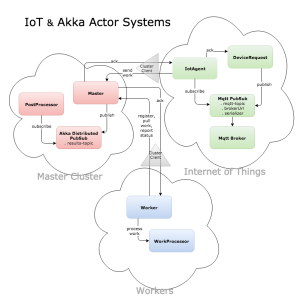
As shown in the diagram, the application consists of the following components:
1. IoT
- A DeviceRequest actor which:
- simulates work requests from IoT devices
- publishes requests to a MQTT pub-sub topic
- re-publishes requests upon receiving failure messages from a topic subscriber
- An IotAgent actor which:
- subscribes to the mqtt-topic for the work requests
- sends received work requests via ClusterClient to the master cluster
- sends DeviceRequest actor a failure message upon receiving failure messages from Master actor
- A MQTT pub-sub client, MqttPubSub, for communicating with a MQTT broker
- A configuration helper object, MqttConfig, consisting of:
- MQTT pub-sub topic
- URL for the MQTT broker
- Serialization methods to convert objects to byte arrays, and vice versa
2. Master Cluster
- A fault-tolerant decentralized cluster which:
- manages a singleton actor instance among the cluster nodes (with a specified role)
- delegates ClusterClientReceptionist on every node to answer external connection requests
- provides fail-over of the singleton actor to the next-oldest node in the cluster
- A Master singleton actor which:
- registers Workers and distributes work to available Workers
- acknowledges work request reception with IotAgent
- publishes work results to a work-results topic via Akka distributed pub-sub
- maintains work states using persistence journal
- A PostProcessor actor in the master cluster which:
- simulates post-processing of the work results
- subscribes to the work-results topic
3. Workers
- An actor system of Workers each of which:
- communicates via ClusterClient with the master cluster
- registers with, pulls work from the Master actor
- reports work status with the Master actor
- instantiates a WorkProcessor actor to perform the actual work
- WorkProcessor actors which process the work requests
Source code is available at GitHub.
A few notes:
- Neither IotAgent nor Worker actor system is a part of the master cluster, hence both need to communicate with the Master via ClusterClient.
- Rather than having the Master actor spawn child Workers and push work over, the Workers are set up to register with the Master and pull work from it – a model similar to what Derek Wyatt advocated in his post.
- Paho-Akka is used as the MQTT pub-sub client with configuration information held within the helper object, MqttConfig.
- The helper object MqttConfig consists of MQTT pub-sub topic/broker information and methods to serialize/deserialize the Work objects which, in turn, contains Device objects. The explicit serializations are necessary since multiple JVMs will be at play if one launches the master cluster, IoT and worker actor systems on separate JVMs.
- The test Mosquitto broker at tcp://test.mosquitto.org:1883 serves as the MQTT broker. An alternative is to install a MQTT broker (Mosquitto, HiveMQ, etc) local to the IoT network.
- The IotAgent uses Actor’s ask method (?), instead of the fire-and-forget tell method (!), to confirm message receipt by the Master via a Future return. If the receipt confirmation is not so important, using the tell method will be a much preferred choice for performance.
- This is primarily a proof-of-concept application of IoT using Akka actors, hence code performance optimization isn’t a priority. In addition, for production systems, a production-grade persistence journal (e.g. Redis, Cassandra) should be used and multiple-Master via sharding could be considered.
Test-running
Similar to how you would test-run Lightbend’s distributed workers template, you may open up separate command line terminals and run the different components on separate JVMs, adding and killing the launched components to observe how the systems scale out, fail over, persist work states, etc. Here’s an example of test-run sequence:
Launch the master cluster seed node with persistence journal: <project-root>/bin/activator "runMain worker.Main 2551" Launch the IotAgent-DeviceRequest node: <project-root>/bin/activator "runMain worker.Main 3001" Launch additional master cluster seed node: <project-root>/bin/activator "runMain worker.Main 2552" Launch the Worker node: <project-root>/bin/activator "runMain worker.Main 0" Launch additional Worker node: <project-root>/bin/activator "runMain worker.Main 0"
Below are some sample console output.
Console Output: Master seed node with persistence journal:
$ bin/activator "runMain worker.Main 2551"
[info] Loading project definition from /Users/leo/apps/scala/akka-iot-mqtt/project/project
[info] Updating {file:/Users/leo/apps/scala/akka-iot-mqtt/project/project/}akka-iot-mqtt-build-build...
...
...
[info] Done updating.
[info] Compiling 12 Scala sources to /Users/leo/apps/scala/akka-iot-mqtt/target/scala-2.11/classes...
background log: info: Running worker.Main 2551
background log: info: [INFO] [04/29/2016 08:54:19.120] [main] [akka.remote.Remoting] Starting remoting
background log: info: [INFO] [04/29/2016 08:54:21.627] [main] [akka.remote.Remoting] Remoting started; listening on addresses :[akka.tcp://ClusterSystem@127.0.0.1:2551]
background log: info: [INFO] [04/29/2016 08:54:21.628] [main] [akka.remote.Remoting] Remoting now listens on addresses: [akka.tcp://ClusterSystem@127.0.0.1:2551]
...
...
background log: info: [INFO] [04/29/2016 08:54:28.140] [ClusterSystem-akka.actor.default-dispatcher-15] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] - Node [akka.tcp://ClusterSystem@127.0.0.1:2551] is JOINING, roles [backend]
background log: info: [INFO] [04/29/2016 08:54:28.974] [ClusterSystem-akka.actor.default-dispatcher-15] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] - Leader is moving node [akka.tcp://ClusterSystem@127.0.0.1:2551] to [Up]
background log: info: [INFO] [04/29/2016 08:54:29.102] [ClusterSystem-akka.actor.default-dispatcher-18] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master] Singleton manager starting singleton actor [akka://ClusterSystem/user/master/singleton]
background log: info: [INFO] [04/29/2016 08:54:29.103] [ClusterSystem-akka.actor.default-dispatcher-18] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master] ClusterSingletonManager state change [Start -> Oldest]
...
...
<<< /bin/activator "runMain worker.Main 2552"
background log: info: [INFO] [04/29/2016 08:57:17.648] [ClusterSystem-akka.actor.default-dispatcher-2] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] - Node [akka.tcp://ClusterSystem@127.0.0.1:2552] is JOINING, roles [backend]
background log: info: [INFO] [04/29/2016 08:57:18.194] [ClusterSystem-akka.actor.default-dispatcher-14] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] - Leader is moving node [akka.tcp://ClusterSystem@127.0.0.1:2552] to [Up]
...
...
background log: info: [INFO] [04/29/2016 08:57:29.043] [ClusterSystem-akka.actor.default-dispatcher-2] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] - Marking node(s) as REACHABLE [Member(address = akka.tcp://ClusterSystem@127.0.0.1:2552, status = Up)]
...
...
<<< [while worker node 0-a is up]
background log: info: [INFO] [04/29/2016 09:05:09.448] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work: Work Id 4fc64049-fa21-49c6-9d54-743eaa055373 | Device Id lamp-5095
background log: info: [INFO] [04/29/2016 09:05:09.930] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work to: Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316 | Work Id 4fc64049-fa21-49c6-9d54-743eaa055373 | Device Id lamp-5095
background log: info: [INFO] [04/29/2016 09:05:09.934] [ClusterSystem-akka.actor.default-dispatcher-45] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Acknowledged work done: Work Id 4fc64049-fa21-49c6-9d54-743eaa055373 | Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316
background log: info: [INFO] [04/29/2016 09:05:10.169] [ClusterSystem-akka.actor.default-dispatcher-20] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/postprocessor] Post-processor -> Got work result NO CHANGE | Work Id 4fc64049-fa21-49c6-9d54-743eaa055373
background log: info: [INFO] [04/29/2016 09:05:15.011] [ClusterSystem-akka.actor.default-dispatcher-45] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work: Work Id a66d1079-5083-491e-9b5e-885e7914426f | Device Id security-alarm-9095
background log: info: [INFO] [04/29/2016 09:05:15.366] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work to: Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316 | Work Id a66d1079-5083-491e-9b5e-885e7914426f | Device Id security-alarm-9095
background log: info: [INFO] [04/29/2016 09:05:15.370] [ClusterSystem-akka.actor.default-dispatcher-45] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Acknowledged work done: Work Id a66d1079-5083-491e-9b5e-885e7914426f | Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316
background log: info: [INFO] [04/29/2016 09:05:15.542] [ClusterSystem-akka.actor.default-dispatcher-20] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/postprocessor] Post-processor -> Got work result Switch light to ON | Work Id a66d1079-5083-491e-9b5e-885e7914426f
background log: info: [INFO] [04/29/2016 09:05:22.412] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work: Work Id bc502538-5baa-494d-8565-5cb91ad27001 | Device Id thermostat-1004
background log: info: [INFO] [04/29/2016 09:05:22.699] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work to: Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316 | Work Id bc502538-5baa-494d-8565-5cb91ad27001 | Device Id thermostat-1004
background log: info: [INFO] [04/29/2016 09:05:22.703] [ClusterSystem-akka.actor.default-dispatcher-43] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Acknowledged work done: Work Id bc502538-5baa-494d-8565-5cb91ad27001 | Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316
background log: info: [INFO] [04/29/2016 09:05:22.798] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/postprocessor] Post-processor -> Got work result LOWER temperature by 1F | Work Id bc502538-5baa-494d-8565-5cb91ad27001
background log: info: [INFO] [04/29/2016 09:05:31.779] [ClusterSystem-akka.actor.default-dispatcher-45] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work: Work Id 1c815602-9666-4c5d-9029-4fdd719f48b4 | Device Id thermostat-1044
background log: info: [INFO] [04/29/2016 09:05:32.065] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work to: Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316 | Work Id 1c815602-9666-4c5d-9029-4fdd719f48b4 | Device Id thermostat-1044
background log: info: [INFO] [04/29/2016 09:05:32.070] [ClusterSystem-akka.actor.default-dispatcher-45] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Acknowledged work done: Work Id 1c815602-9666-4c5d-9029-4fdd719f48b4 | Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316
background log: info: [INFO] [04/29/2016 09:05:32.257] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/postprocessor] Post-processor -> Got work result RAISE temperature by 2F | Work Id 1c815602-9666-4c5d-9029-4fdd719f48b4
background log: info: [INFO] [04/29/2016 09:05:36.169] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work: Work Id fadc48cf-a8c7-4942-bd35-d97b7acf8ad9 | Device Id lamp-5471
background log: info: [INFO] [04/29/2016 09:05:36.359] [ClusterSystem-akka.actor.default-dispatcher-39] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work to: Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316 | Work Id fadc48cf-a8c7-4942-bd35-d97b7acf8ad9 | Device Id lamp-5471
background log: info: [INFO] [04/29/2016 09:05:36.363] [ClusterSystem-akka.actor.default-dispatcher-43] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Acknowledged work done: Work Id fadc48cf-a8c7-4942-bd35-d97b7acf8ad9 | Worker Id f3c61905-f624-46ca-9e4e-b3b0374fa316
background log: info: [INFO] [04/29/2016 09:05:36.496] [ClusterSystem-akka.actor.default-dispatcher-39] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/postprocessor] Post-processor -> Got work result Switch light to ON | Work Id fadc48cf-a8c7-4942-bd35-d97b7acf8ad9
...
...
<<< [downing worker node 54323]
background log: info: [WARN] [04/29/2016 09:12:43.526] [ClusterSystem-akka.remote.default-remote-dispatcher-34] [akka.tcp://ClusterSystem@127.0.0.1:2551/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FWorkerSystem%40127.0.0.1%3A54323-3] Association with remote system [akka.tcp://WorkerSystem@127.0.0.1:54323] has failed, address is now gated for [5000] ms. Reason: [Disassociated]
background log: info: [INFO] [04/29/2016 09:12:50.846] [ClusterSystem-akka.actor.default-dispatcher-49] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Accepted work: Work Id ea8f92ae-776f-4bd0-87b4-5ad3992b1daa | Device Id lamp-5210
background log: info: [INFO] [04/29/2016 09:12:50.884] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Delegating work to: Worker Id 68a11934-16ca-4bbb-a8c9-27d5a4ac5ede | Work Id ea8f92ae-776f-4bd0-87b4-5ad3992b1daa | Device Id lamp-5210
background log: info: [INFO] [04/29/2016 09:12:51.009] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master/singleton] Cluster Master -> Acknowledged work done: Work Id ea8f92ae-776f-4bd0-87b4-5ad3992b1daa | Worker Id 68a11934-16ca-4bbb-a8c9-27d5a4ac5ede
background log: info: [INFO] [04/29/2016 09:12:51.010] [ClusterSystem-akka.actor.default-dispatcher-39] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/postprocessor] Post-processor -> Got work result Switch light to ON | Work Id ea8f92ae-776f-4bd0-87b4-5ad3992b1daa
...
...
<<< [downing worker node 54351]
background log: info: [WARN] [04/29/2016 09:18:07.161] [ClusterSystem-akka.remote.default-remote-dispatcher-38] [akka.tcp://ClusterSystem@127.0.0.1:2551/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FWorkerSystem%40127.0.0.1%3A54351-5] Association with remote system [akka.tcp://WorkerSystem@127.0.0.1:54351] has failed, address is now gated for [5000] ms. Reason: [Disassociated]
...
...
<<< [downing iot-device node 3001]
background log: info: [WARN] [04/29/2016 09:18:43.385] [ClusterSystem-akka.remote.default-remote-dispatcher-38] [akka.tcp://ClusterSystem@127.0.0.1:2551/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FIotSystem%40127.0.0.1%3A3001-8] Association with remote system [akka.tcp://IotSystem@127.0.0.1:3001] has failed, address is now gated for [5000] ms. Reason: [Disassociated]
...
...
<<< [downing cluster seed node 2552]
background log: info: [WARN] [04/29/2016 09:18:53.937] [ClusterSystem-akka.remote.default-remote-dispatcher-34] [akka.tcp://ClusterSystem@127.0.0.1:2551/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2552-0] Association with remote system [akka.tcp://ClusterSystem@127.0.0.1:2552] has failed, address is now gated for [5000] ms. Reason: [Disassociated]
...
...
background log: info: [INFO] [04/29/2016 09:19:07.754] [ClusterSystem-akka.actor.default-dispatcher-43] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] - Leader is auto-downing unreachable node [akka.tcp://ClusterSystem@127.0.0.1:2552]
background log: info: [INFO] [04/29/2016 09:19:07.783] [ClusterSystem-akka.actor.default-dispatcher-43] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] - Marking unreachable node [akka.tcp://ClusterSystem@127.0.0.1:2552] as [Down]
background log: info: [INFO] [04/29/2016 09:19:08.775] [ClusterSystem-akka.actor.default-dispatcher-51] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] - Leader is removing unreachable node [akka.tcp://ClusterSystem@127.0.0.1:2552]
background log: info: [INFO] [04/29/2016 09:19:08.776] [ClusterSystem-akka.actor.default-dispatcher-41] [akka.tcp://ClusterSystem@127.0.0.1:2551/user/master] Member removed [akka.tcp://ClusterSystem@127.0.0.1:2552]
background log: info: [WARN] [04/29/2016 09:19:08.861] [ClusterSystem-akka.remote.default-remote-dispatcher-38] [akka.remote.Remoting] Association to [akka.tcp://ClusterSystem@127.0.0.1:2552] having UID [113992052] is irrecoverably failed. UID is now quarantined and all messages to this UID will be delivered to dead letters. Remote actorsystem must be restarted to recover from this situation.
Console Output: IotAgent-DeviceRequest node:
$ bin/activator "runMain worker.Main 3001" [info] Loading project definition from /Users/leo/apps/scala/akka-iot-mqtt/project/project [info] Loading project definition from /Users/leo/apps/scala/akka-iot-mqtt/project [info] Set current project to akka-iot-mqtt (in build file:/Users/leo/apps/scala/akka-iot-mqtt/) background log: info: Running worker.Main 3001 background log: info: [INFO] [04/29/2016 09:00:42.224] [main] [akka.remote.Remoting] Starting remoting background log: info: [INFO] [04/29/2016 09:00:42.664] [main] [akka.remote.Remoting] Remoting started; listening on addresses :[akka.tcp://IotSystem@127.0.0.1:3001] background log: info: [INFO] [04/29/2016 09:00:42.665] [main] [akka.remote.Remoting] Remoting now listens on addresses: [akka.tcp://IotSystem@127.0.0.1:3001] background log: info: [INFO] [04/29/2016 09:00:44.563] [IotSystem-akka.actor.default-dispatcher-2] [akka.tcp://IotSystem@127.0.0.1:3001/user/clusterClient] Connected to [akka.tcp://ClusterSystem@127.0.0.1:2552/system/receptionist] background log: info: 09:00:45.632 [IotSystem-akka.actor.default-dispatcher-3] INFO com.sandinh.paho.akka.MqttPubSub - connecting to tcp://test.mosquitto.org:1883.. background log: info: 09:00:46.330 [MQTT Call: paho329851808627927] INFO com.sandinh.paho.akka.MqttPubSub - connected background log: info: [INFO] [04/29/2016 09:00:46.334] [IotSystem-akka.actor.default-dispatcher-2] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> MQTT subscription to akka-iot-mqtt-topic acknowledged background log: info: 09:00:46.513 [MQTT Call: paho329851808627927] INFO com.sandinh.paho.akka.MqttPubSub - subscribed to [akka-iot-mqtt-topic] background log: info: [INFO] [04/29/2016 09:00:49.413] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Device Id security-alarm-9094 | Device State OFF background log: info: [INFO] [04/29/2016 09:00:49.553] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Publishing MQTT Topic akka-iot-mqtt-topic: Device Id security-alarm-9094 | Device State OFF background log: info: 09:00:49.555 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - delivery complete [akka-iot-mqtt-topic] background log: info: 09:00:49.736 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - message arrived akka-iot-mqtt-topic background log: info: [INFO] [04/29/2016 09:00:49.738] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Received MQTT message: Device Id security-alarm-9094 | Device State OFF | Work Id 9016bdbd-e70d-4546-8cc8-6719c02f8404 background log: info: [INFO] [04/29/2016 09:00:49.738] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Sending work to cluster master ... ... background log: info: [INFO] [04/29/2016 09:05:09.264] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Device Id lamp-5095 | Device State ON background log: info: [INFO] [04/29/2016 09:05:09.264] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Publishing MQTT Topic akka-iot-mqtt-topic: Device Id lamp-5095 | Device State ON background log: info: 09:05:09.265 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - delivery complete [akka-iot-mqtt-topic] background log: info: 09:05:09.444 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - message arrived akka-iot-mqtt-topic background log: info: [INFO] [04/29/2016 09:05:09.445] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Received MQTT message: Device Id lamp-5095 | Device State ON | Work Id 4fc64049-fa21-49c6-9d54-743eaa055373 background log: info: [INFO] [04/29/2016 09:05:09.445] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Sending work to cluster master background log: info: [INFO] [04/29/2016 09:05:14.674] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Device Id security-alarm-9095 | Device State OFF background log: info: [INFO] [04/29/2016 09:05:14.675] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Publishing MQTT Topic akka-iot-mqtt-topic: Device Id security-alarm-9095 | Device State OFF background log: info: 09:05:14.675 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - delivery complete [akka-iot-mqtt-topic] background log: info: 09:05:15.008 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - message arrived akka-iot-mqtt-topic background log: info: [INFO] [04/29/2016 09:05:15.008] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Received MQTT message: Device Id security-alarm-9095 | Device State OFF | Work Id a66d1079-5083-491e-9b5e-885e7914426f background log: info: [INFO] [04/29/2016 09:05:15.008] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Sending work to cluster master background log: info: [INFO] [04/29/2016 09:05:22.213] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Device Id thermostat-1004 | Device State HEAT background log: info: [INFO] [04/29/2016 09:05:22.213] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Publishing MQTT Topic akka-iot-mqtt-topic: Device Id thermostat-1004 | Device State HEAT background log: info: 09:05:22.229 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - delivery complete [akka-iot-mqtt-topic] background log: info: 09:05:22.409 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - message arrived akka-iot-mqtt-topic background log: info: [INFO] [04/29/2016 09:05:22.409] [IotSystem-akka.actor.default-dispatcher-4] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Received MQTT message: Device Id thermostat-1004 | Device State HEAT | Work Id bc502538-5baa-494d-8565-5cb91ad27001 background log: info: [INFO] [04/29/2016 09:05:22.409] [IotSystem-akka.actor.default-dispatcher-4] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Sending work to cluster master background log: info: [INFO] [04/29/2016 09:05:31.593] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Device Id thermostat-1044 | Device State HEAT background log: info: [INFO] [04/29/2016 09:05:31.593] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Publishing MQTT Topic akka-iot-mqtt-topic: Device Id thermostat-1044 | Device State HEAT background log: info: 09:05:31.593 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - delivery complete [akka-iot-mqtt-topic] background log: info: 09:05:31.776 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - message arrived akka-iot-mqtt-topic background log: info: [INFO] [04/29/2016 09:05:31.777] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Received MQTT message: Device Id thermostat-1044 | Device State HEAT | Work Id 1c815602-9666-4c5d-9029-4fdd719f48b4 background log: info: [INFO] [04/29/2016 09:05:31.777] [IotSystem-akka.actor.default-dispatcher-3] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Sending work to cluster master background log: info: [INFO] [04/29/2016 09:05:35.983] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Device Id lamp-5471 | Device State OFF background log: info: [INFO] [04/29/2016 09:05:35.983] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/devicerequest] Device Request -> Publishing MQTT Topic akka-iot-mqtt-topic: Device Id lamp-5471 | Device State OFF background log: info: 09:05:35.984 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - delivery complete [akka-iot-mqtt-topic] background log: info: 09:05:36.166 [MQTT Call: paho329851808627927] DEBUG com.sandinh.paho.akka.MqttPubSub - message arrived akka-iot-mqtt-topic background log: info: [INFO] [04/29/2016 09:05:36.166] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Received MQTT message: Device Id lamp-5471 | Device State OFF | Work Id fadc48cf-a8c7-4942-bd35-d97b7acf8ad9 background log: info: [INFO] [04/29/2016 09:05:36.166] [IotSystem-akka.actor.default-dispatcher-14] [akka.tcp://IotSystem@127.0.0.1:3001/user/iotagent] IoT Agent -> Sending work to cluster master ... ...
Console Output: Worker node:
$ bin/activator "runMain worker.Main 0" [info] Loading project definition from /Users/leo/apps/scala/akka-iot-mqtt/project/project [info] Loading project definition from /Users/leo/apps/scala/akka-iot-mqtt/project [info] Set current project to akka-iot-mqtt (in build file:/Users/leo/apps/scala/akka-iot-mqtt/) background log: info: Running worker.Main 0 background log: info: [INFO] [04/29/2016 09:02:21.265] [main] [akka.remote.Remoting] Starting remoting background log: info: [INFO] [04/29/2016 09:02:23.385] [main] [akka.remote.Remoting] Remoting started; listening on addresses :[akka.tcp://WorkerSystem@127.0.0.1:54323] background log: info: [INFO] [04/29/2016 09:02:23.419] [main] [akka.remote.Remoting] Remoting now listens on addresses: [akka.tcp://WorkerSystem@127.0.0.1:54323] background log: info: [INFO] [04/29/2016 09:02:26.278] [WorkerSystem-akka.actor.default-dispatcher-3] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/clusterClient] Connected to [akka.tcp://ClusterSystem@127.0.0.1:2552/system/receptionist] ... ... background log: info: [INFO] [04/29/2016 09:05:09.932] [WorkerSystem-akka.actor.default-dispatcher-16] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Received work request: Job Adjust device | Device Id lamp-5095 | Device State ON background log: info: [INFO] [04/29/2016 09:05:09.932] [WorkerSystem-akka.actor.default-dispatcher-16] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Finished work: Action NO CHANGE | Work Id 4fc64049-fa21-49c6-9d54-743eaa055373 background log: info: [INFO] [04/29/2016 09:05:15.368] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Received work request: Job Adjust device | Device Id security-alarm-9095 | Device State OFF background log: info: [INFO] [04/29/2016 09:05:15.368] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Finished work: Action Switch light to ON | Work Id a66d1079-5083-491e-9b5e-885e7914426f background log: info: [INFO] [04/29/2016 09:05:22.701] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Received work request: Job Adjust device | Device Id thermostat-1004 | Device State HEAT background log: info: [INFO] [04/29/2016 09:05:22.701] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Finished work: Action LOWER temperature by 1F | Work Id bc502538-5baa-494d-8565-5cb91ad27001 background log: info: [INFO] [04/29/2016 09:05:32.068] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Received work request: Job Adjust device | Device Id thermostat-1044 | Device State HEAT background log: info: [INFO] [04/29/2016 09:05:32.068] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Finished work: Action RAISE temperature by 2F | Work Id 1c815602-9666-4c5d-9029-4fdd719f48b4 background log: info: [INFO] [04/29/2016 09:05:36.361] [WorkerSystem-akka.actor.default-dispatcher-4] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Received work request: Job Adjust device | Device Id lamp-5471 | Device State OFF background log: info: [INFO] [04/29/2016 09:05:36.361] [WorkerSystem-akka.actor.default-dispatcher-3] [akka.tcp://WorkerSystem@127.0.0.1:54323/user/worker] Worker -> Finished work: Action Switch light to ON | Work Id fadc48cf-a8c7-4942-bd35-d97b7acf8ad9 ... ...