
Borne out of Google and open-sourced in 2015, gRPC is a RPC framework which has been increasingly talked about over the past few years. In case you’re curious about what the g in gRPC stands for, it turns out the the term is a peculiar recursive acronym of gRPC Remote Procedure Calls.
gRPC uses Protocol Buffers for serialization and as its IDL (Interface Definition Language). It also relies on HTTP/2 as its transport. While HTTP/2 has been growing in demand, its adoption rate is still rather slow. As of this writing, only slightly over 1/3 of websites support HTTP/2. That inevitably slows down gRPC’s adoption. Nevertheless, it’s hard to ignore the goodies it offers. In particular, gRPC has been known for its strength for building systems that demand a microservices design with fast inter-service calls with de-coupled interfaces across polyglot services. A comprehensive list of its benefits is available in this Akka gRPC tech doc section.
Akka gRPC
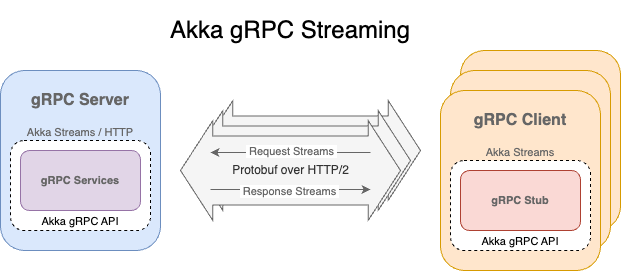
Operating on top of Akka Streams and Akka HTTP, Akka gRPC provides support for building streaming gRPC servers and clients.
On the server side, Akka gRPC generates service interfaces (as Scala traits) based on the individual services defined in the Protobuf schema. The server-side programming logic can then be crafted as specific service implementations. Akka gRPC also generates from the Protobuf services definition a number of service handlers that take the service implementation as an input parameter and return a HttpRequest => Future[HttpResponse] route in Akka-HTTP.
As for the client side, a client program would use the service stubs generated by Akka gRPC (through implementing the service interfaces) to invoke the remote services. The following diagram highlights what a streaming gRPC server and clients might look like.
IoT systems of sensor devices
In many use cases, an IoT (Internet of Things) system of sensor devices consists of a large amount of devices running on some LAN/WiFi or wireless personal area networks (WPAN). A previous blog post of mine re: running IoT sensor devices using Akka’s distributed pub/sub in Scala illustrates how an Akka Actor-based cluster fits into managing large-scale interactive IoT devices.
This time, rather than centering the IoT system around an actor model, we’re going to implement the system using Akka gRPC in Scala, leveraging the robust Akka Streams API applied in accordance with the Protobuf services definition and running on an HTTP/2 compliant server.
A simple use case
We’ll start with a simple use case. Let’s say we have an optimization algorithm running on a server that analyzes current operational states of a given IoT sensor device (e.g. a thermostat) and returns revised states.
On the client side, there can be many clients, each handles the sensor devices for a specific group of real estate properties. Each client application would submit to the server the current operational states and settings of the devices, as a stream of state-update requests.
The server would then run of the optimization algorithm based on each device’s current state and setting and the property it’s in to return an object with revised state and setting, as an element of the response stream. In this use case, the response stream will be received by the same client firing off the request stream.
Each device has the following attributes:
- deviceType:
- 0 = Thermostat
- 1 = Lamp
- 2 = SecurityAlarm
- opState:
- devType 0 => 0 | 1 | 2 (OFF | HEAT | COOL)
- devType 1 => 0 | 1 (OFF | ON)
- devType 2 => 0 | 1 (OFF | ON)
- setting:
- devType 0 => 60 – 75
- devType 1 => 1 – 3
- devType 2 => 1 – 5
A slightly more complex use case that involves dynamically broadcasting response streams from the server to participating clients will be discussed in a subsequent blog post.
Library dependencies
Using sbt as the build tool, build.sbt would look like this:
name := "akka-grpc-iot-stream" version := "1.0" scalaVersion := "2.13.4" lazy val akkaVersion = "2.8.5" lazy val akkaHttpVersion = "10.5.2" lazy val akkaGrpcVersion = "2.3.4" enablePlugins(AkkaGrpcPlugin) fork := true libraryDependencies ++= Seq( "com.typesafe.akka" %% "akka-http" % akkaHttpVersion, "com.typesafe.akka" %% "akka-http2-support" % akkaHttpVersion, "com.typesafe.akka" %% "akka-actor-typed" % akkaVersion, "com.typesafe.akka" %% "akka-stream" % akkaVersion, "com.typesafe.akka" %% "akka-discovery" % akkaVersion, "com.typesafe.akka" %% "akka-pki" % akkaVersion, "com.typesafe.akka" %% "akka-http" % akkaHttpVersion, "com.typesafe.akka" %% "akka-http2-support" % akkaHttpVersion, "ch.qos.logback" % "logback-classic" % "1.2.3" )
Note that AkkaGrpcPlugin is the plug-in that carries out all the gRPC generator functions with akka-http2-support ensuring the necessary HTTP/2 support for gRPC.
The IotDevice class
First, we come up with the IotDevice class that represents our IoT sensor devices. For illustration purpose, we add a withRandomStates() method within the companion object for creating an IotDevice object initialized with random states.
object DeviceType extends Enumeration {
type DeviceType = Value
val Thermostat: Value = Value(0)
val Lamp: Value = Value(1)
val SecurityAlarm: Value = Value(2)
}
case class IotDevice( deviceId: String,
deviceType: Int,
propertyId: Int,
timestamp: Long,
opState: Int,
setting: Int )
object IotDevice {
def withRandomStates(propertyId: Int): IotDevice = {
val devType = randomInt(0, 3) // 0 -> Thermostat | 1 -> Lamp | 2 -> SecurityAlarm
val (opState: Int, setting: Int) = devType match {
case 0 => (randomInt(0, 3), randomInt(60, 76)) // 0|1|2 (OFF|HEAT|COOL), 60-75
case 1 => (randomInt(0, 2), randomInt(1, 4)) // 0|1 (OFF|ON), 1-3
case 2 => (randomInt(0, 2), randomInt(1, 6)) // 0|1 (OFF|ON), 1-5
}
IotDevice(
randomId(),
devType,
propertyId,
System.currentTimeMillis(),
opState,
setting
)
}
}
Protobuf schema
Next, we define our request/response messages and RPC services in file src/main/protobuf/iotstream.proto:
syntax = "proto3";
option java_multiple_files = true;
option java_package = "akkagrpc";
option java_outer_classname = "IotStreamProto";
service IotStreamService {
rpc sendIotUpdate(stream StatesUpdateRequest) returns (stream StatesUpdateResponse) {}
}
message StatesUpdateRequest {
string id = 1;
string client_id = 2;
int32 property_id = 3;
string device_id = 4;
int32 device_type = 5;
int64 timestamp = 6;
int32 op_state = 7;
int32 setting = 8;
}
message StatesUpdateResponse {
string id = 1;
string client_id = 2;
int32 property_id = 3;
string device_id = 4;
int32 device_type = 5;
int64 timestamp = 6;
int32 op_state_new = 7;
int32 setting_new = 8;
}
As shown in the Protobuf schema, messages StatesUpdateRequest and StatesUpdateResponse define the request and response streams for the gRPC application, whereas service IotStreamService reveals the signature of the RPC service, leaving its business logic in be implemented in Scala code.
Classes generated by Akka gRPC
The AkkaGrpcPlugin automatically generates Scala source code equivalent to the defined Protobuf messages and to-be-implemented RPC services as Scala traits and classes, along with Akka Stream flows and Akka HTTP routes. The generated classes are placed under target/scala-<scalaVersion>/akka-grpc/main/akkagrpc/:
- IotstreamProto.scala
- IotStreamService.scala
- IotStreamServiceHandler.scala
- IotStreamServiceClient.scala
- StatesUpdateRequest.scala
- StatesUpdateResponse.scala
Service implementation
Now that the generated service interfaces and handlers are in place, we’re ready to create our specific service implementation as class IotStreamServiceImpl:
package akkagrpc
import akka.NotUsed
import akka.actor.typed.ActorSystem
import akka.stream.scaladsl._
import scala.concurrent.duration._
import java.util.UUID
import java.util.concurrent.ThreadLocalRandom
class IotStreamServiceImpl(system: ActorSystem[_]) extends IotStreamService {
private implicit val sys: ActorSystem[_] = system
val backpressureTMO: FiniteDuration = 3.seconds
val updateIotFlow: Flow[StatesUpdateRequest, StatesUpdateResponse, NotUsed] =
Flow[StatesUpdateRequest]
.map { case StatesUpdateRequest(id, clientId, propId, devId, devType, ts, opState, setting, _) =>
val (opStateNew, settingNew) =
updateDeviceStates(propId, devId, devType, opState, setting)
StatesUpdateResponse(
randomId(),
clientId,
propId,
devId,
devType,
System.currentTimeMillis(),
opStateNew,
settingNew)
}
@Override
def sendIotUpdate(requests: Source[StatesUpdateRequest, NotUsed]): Source[StatesUpdateResponse, NotUsed] =
requests.via(updateIotFlow).backpressureTimeout(backpressureTMO)
def updateDeviceStates(propId: Int, devId: String, devType: Int, opState: Int, setting: Int): (Int, Int) = {
// Random device states update simulating algorithmic adjustment in accordance with device and
// property specific factors (temperature, lighting, etc)
devType match {
case 0 =>
val opStateNew =
if (opState == 0) randomInt(0, 3) else {
if (opState == 1) randomInt(0, 2) else (2 + randomInt(0, 2)) % 3
}
val settingTemp = setting + randomInt(-2, 3)
val settingNew = if (settingTemp < 60) 60 else if (settingTemp > 75) 75 else settingTemp
(opStateNew, settingNew)
case 1 =>
(randomInt(0, 2), randomInt(1, 4))
case 2 =>
(randomInt(0, 2), randomInt(1, 6))
}
}
def randomInt(a: Int, b: Int): Int = ThreadLocalRandom.current().nextInt(a, b)
def randomId(): String = UUID.randomUUID().toString.slice(0, 6) // UUID's first 6 chars
}
Encapsulating the device states update simulation logic, the Akka Stream flow updateIotFlow creates the stream to be carried out by the sendIotUpdate() RPC — all handled by Akka gRPC behind the scene.
TLS-enabled HTTP/2 server
For a skeletal HTTP/2 compliant server, we create class IotStreamServer by borrowing part of the GreeterService sample code available at Lightbend developers guide.
package akkagrpc
import java.security.{KeyStore, SecureRandom}
import java.security.cert.{Certificate, CertificateFactory}
import akka.actor.typed.ActorSystem
import akka.actor.typed.scaladsl.Behaviors
import akka.http.scaladsl.{ConnectionContext, Http, HttpsConnectionContext}
import akka.http.scaladsl.model.{HttpRequest, HttpResponse}
import akka.pki.pem.{DERPrivateKeyLoader, PEMDecoder}
import com.typesafe.config.ConfigFactory
import javax.net.ssl.{KeyManagerFactory, SSLContext}
import scala.concurrent.{ExecutionContext, Future}
import scala.concurrent.duration._
import scala.util.{Success, Failure}
import scala.io.Source
object IotStreamServer {
def main(args: Array[String]): Unit = {
// important to enable HTTP/2 in ActorSystem's config
val conf = ConfigFactory.parseString("akka.http.server.preview.enable-http2 = on")
.withFallback(ConfigFactory.defaultApplication())
val system = ActorSystem[Nothing](Behaviors.empty, "IotStreamServer", conf)
new IotStreamServer(system).run()
}
}
class IotStreamServer(system: ActorSystem[_]) {
def run(): Future[Http.ServerBinding] = {
implicit val sys = system
implicit val ec: ExecutionContext = system.executionContext
val service: HttpRequest => Future[HttpResponse] =
IotStreamServiceHandler(new IotStreamServiceImpl(system))
val boundServer: Future[Http.ServerBinding] = Http(system)
.newServerAt(interface = "127.0.0.1", port = 8080)
.enableHttps(serverHttpContext)
.bind(service)
.map(_.addToCoordinatedShutdown(hardTerminationDeadline = 10.seconds))
boundServer.onComplete {
case Success(binding) =>
val address = binding.localAddress
Console.out.println(s"[Server] gRPC server bound to ${address.getHostString}:${address.getPort}")
case Failure(ex) =>
Console.err.println("[Server] ERROR: Failed to bind gRPC endpoint, terminating system ", ex)
system.terminate()
}
boundServer
}
private def serverHttpContext: HttpsConnectionContext = {
val privateKey =
DERPrivateKeyLoader.load(PEMDecoder.decode(readPrivateKeyPem()))
val fact = CertificateFactory.getInstance("X.509")
val cer = fact.generateCertificate(
classOf[IotStreamServer].getResourceAsStream("/certs/server1.pem")
)
val ks = KeyStore.getInstance("PKCS12")
ks.load(null)
ks.setKeyEntry(
"private",
privateKey,
new Array[Char](0),
Array[Certificate](cer)
)
val keyManagerFactory = KeyManagerFactory.getInstance("SunX509")
keyManagerFactory.init(ks, null)
val context = SSLContext.getInstance("TLS")
context.init(keyManagerFactory.getKeyManagers, null, new SecureRandom)
ConnectionContext.httpsServer(context)
}
private def readPrivateKeyPem(): String =
Source.fromResource("certs/server1.key").mkString
}
For development purposes, contrary to just having a self-signed PKCS#12 certificate for a TLS-enabled HTTP server, gRPC clients have more stringent requirement, demanding a HTTP server certificate along with a valid Certificate Authority (CA) certificate that signs the server cert. Rather than going through the process of creating our own CA, for just demonstration purpose, we use the CA certificate that comes with the GreeterService code. The host, port number along with the CA certificate file path are configured for the gRPC client within application.conf, which has content like below:
akka.grpc.client {
"akkagrpc.IotStreamService" {
host = 127.0.0.1
port = 8080
override-authority = foo.test.google.fr
trusted = /certs/ca.pem
}
}
The client application
As shown in the source code of IotStreamClient, the client app passes a stream of states update requests from a group of real estate properties as parameters to method sendIotUpdate() in the gRPC stub IotStreamServiceClient generated by Akka gRPC.
package akkagrpc
import akka.{Done, NotUsed}
import akka.actor.typed.ActorSystem
import akka.actor.typed.scaladsl.Behaviors
import akka.grpc.GrpcClientSettings
import akka.stream.scaladsl.Source
import akka.stream.ThrottleMode.Shaping
import scala.concurrent.{ExecutionContext, Future}
import scala.util.{Failure, Success, Try}
import scala.concurrent.duration._
import Util._
// akkagrpc.IotStreamClient clientId propIdStart propIdEnd
// e.g. akkagrpc.IotStreamClient client1 1000 1049
object IotStreamClient {
def getDevicesByProperty(propId: Int): Iterator[IotDevice] =
(1 to randomInt(1, 5)).map { _ => // 1-4 devices per property
IotDevice.withRandomStates(propId)
}.iterator
def main(args: Array[String]): Unit = {
implicit val sys: ActorSystem[_] = ActorSystem(Behaviors.empty, "IotStreamClient")
implicit val ec: ExecutionContext = sys.executionContext
val client = IotStreamServiceClient(GrpcClientSettings.fromConfig("akkagrpc.IotStreamService"))
val (clientId: String, broadcastYN: Int, propIdStart: Int, propIdEnd: Int) =
if (args.length == 3) {
Try((args(0), args(1).toInt, args(2).toInt) match {
case Success((cid, pid1, pid2)) =>
(cid, pid1, pid2)
case _ =>
Console.err.println("[Main] ERROR: Arguments required: clientId, propIdStart & propIdEnd e.g. client1 1000 1049")
System.exit(1)
}
}
else
("client1", 1000, 1029) // Default clientId & property id range (inclusive)
val devices: Iterator[IotDevice] =
(propIdStart to propIdEnd).flatMap(getDevicesByProperty).iterator
Console.out.println(s"Performing streaming requests from $clientId ...")
grpcStreaming(clientId)
def grpcStreaming(clientId: String): Unit = {
val requestStream: Source[StatesUpdateRequest, NotUsed] =
Source
.fromIterator(() => devices)
.map { case IotDevice(devId, devType, propId, ts, opState, setting) =>
Console.out.println(s"[$clientId] REQUEST: $propId $devId ${DeviceType(devType)} | State: $opState, Setting: $setting")
StatesUpdateRequest(randomId(), clientId, propId, devId, devType, ts, opState, setting)
}
.throttle(1, 100.millis, 10, Shaping) // For illustration only
val responseStream: Source[StatesUpdateResponse, NotUsed] = client.sendIotUpdate(requestStream)
val done: Future[Done] =
responseStream.runForeach {
case StatesUpdateResponse(id, clntId, propId, devId, devType, ts, opState, setting, _) =>
Console.out.println(s"[$clientId] RESPONSE: [requester: $clntId] $propId $devId ${DeviceType(devType)} | State: $opState, Setting: $setting")
}
done.onComplete {
case Success(_) =>
Console.out.println(s"[$clientId] Done IoT states streaming.")
case Failure(e) =>
Console.err.println(s"[$clientId] ERROR: $e")
}
Thread.sleep(2000)
}
}
}
Running the applications
To run the server application, open a command line terminal and run as follows:
# On terminal #1
cd <project-root>
sbt "runMain akkagrpc.IotStreamServer"For the client application, open a terminal for each client to run a specific range of IDs of real estate properties:
# On terminal #2
cd <project-root>
sbt "runMain akkagrpc.IotStreamClient client1 1000 1019"
# On terminal #3
cd <project-root>
sbt "runMain akkagrpc.IotStreamClient client2 1020 1039"
Below are sample output of the gRPC server and a couple of clients.
Terminal #1: gRPC Server
% ./sbt "runMain akkagrpc.IotStreamServer" [info] compiling ... [info] done compiling [info] running (fork) akkagrpc.IotStreamServer [info] [2023-10-23 11:36:53,173] [INFO] [akka.event.slf4j.Slf4jLogger] [IotStreamServer-akka.actor.default-dispatcher-3] [] - Slf4jLogger started [info] [Server] gRPC server bound to 127.0.0.1:8080
Terminal #2: gRPC Client1
% ./sbt "runMain akkagrpc.IotStreamClient client1 1000 1019" [info] welcome to sbt 1.9.6 (Oracle Corporation Java 11.0.19) [info] loading global plugins from /Users/leo/.sbt/1.0/plugins [info] loading settings for project akka-grpc-iot-stream-build from plugins.sbt ... [info] loading project definition from /Users/leo/intellij/akka-grpc-iot-stream/project [info] loading settings for project akka-grpc-iot-stream from build.sbt ... [info] set current project to akka-grpc-iot-stream (in build file:/Users/leo/intellij/akka-grpc-iot-stream/) [info] running (fork) akkagrpc.IotStreamClient client1 0 1000 1019 [info] [2023-10-18 11:37:19,401] [INFO] [akka.event.slf4j.Slf4jLogger] [IotStreamClient-akka.actor.default-dispatcher-4] [] - Slf4jLogger started [info] Performing streaming requests from client1 ... [info] [client1] REQUEST: 1000 76a2cb Thermostat | State: 1, Setting: 65 [info] [client1] REQUEST: 1001 6588b0 SecurityAlarm | State: 0, Setting: 3 [info] [client1] REQUEST: 1001 2f9150 Lamp | State: 0, Setting: 3 [info] [client1] REQUEST: 1001 a33bd1 SecurityAlarm | State: 0, Setting: 2 [info] [client1] REQUEST: 1001 eabc4b SecurityAlarm | State: 1, Setting: 4 [info] [client1] REQUEST: 1002 c57009 Thermostat | State: 1, Setting: 70 [info] [client1] REQUEST: 1003 4a038c Lamp | State: 0, Setting: 2 [info] [client1] REQUEST: 1003 06bc8b Thermostat | State: 1, Setting: 65 [info] [client1] REQUEST: 1004 ad9432 Lamp | State: 1, Setting: 3 [info] [client1] REQUEST: 1004 356ef0 Lamp | State: 1, Setting: 1 [info] [client1] REQUEST: 1004 f12061 Thermostat | State: 2, Setting: 61 [info] [client1] REQUEST: 1004 983c20 Lamp | State: 0, Setting: 1 [info] [client1] REQUEST: 1005 087963 SecurityAlarm | State: 1, Setting: 3 [info] [client1] RESPONSE: [requester: client1] 1000 76a2cb Thermostat | State: 1, Setting: 63 [info] [client1] RESPONSE: [requester: client1] 1001 6588b0 SecurityAlarm | State: 1, Setting: 1 [info] [client1] RESPONSE: [requester: client1] 1001 2f9150 Lamp | State: 0, Setting: 3 [info] [client1] RESPONSE: [requester: client1] 1001 a33bd1 SecurityAlarm | State: 1, Setting: 3 [info] [client1] RESPONSE: [requester: client1] 1001 eabc4b SecurityAlarm | State: 0, Setting: 1 . . . . . . [info] [client1] REQUEST: 1019 799659 Lamp | State: 1, Setting: 3 [info] [client1] RESPONSE: [requester: client1] 1019 194f79 Thermostat | State: 2, Setting: 63 [info] [client1] REQUEST: 1019 cbdf82 Thermostat | State: 0, Setting: 66 [info] [client1] RESPONSE: [requester: client1] 1019 799659 Lamp | State: 1, Setting: 3 [info] [client1] REQUEST: 1019 76307e SecurityAlarm | State: 1, Setting: 1 [info] [client1] RESPONSE: [requester: client1] 1019 cbdf82 Thermostat | State: 0, Setting: 64 [info] [client1] RESPONSE: [requester: client1] 1019 76307e SecurityAlarm | State: 0, Setting: 4 [info] [client1] Done IoT states streaming.
Terminal #3: gRPC Client2
% ./sbt "runMain akkagrpc.IotStreamClient client2 1020 1039" [info] welcome to sbt 1.9.6 (Oracle Corporation Java 11.0.19) [info] loading global plugins from /Users/leo/.sbt/1.0/plugins [info] loading settings for project akka-grpc-iot-stream-build from plugins.sbt ... [info] loading project definition from /Users/leo/intellij/akka-grpc-iot-stream/project [info] loading settings for project akka-grpc-iot-stream from build.sbt ... [info] set current project to akka-grpc-iot-stream (in build file:/Users/leo/intellij/akka-grpc-iot-stream/) [info] running (fork) akkagrpc.IotStreamClient client2 0 1020 1039 [info] [2023-10-18 11:37:19,401] [INFO] [akka.event.slf4j.Slf4jLogger] [IotStreamClient-akka.actor.default-dispatcher-3] [] - Slf4jLogger started [info] Performing streaming requests from client2 ... [info] [client2] REQUEST: 1020 2cb5a8 Thermostat | State: 0, Setting: 71 [info] [client2] REQUEST: 1020 1a6b0e Lamp | State: 1, Setting: 3 [info] [client2] REQUEST: 1020 d1bd73 Thermostat | State: 2, Setting: 60 [info] [client2] REQUEST: 1020 5d9f65 Thermostat | State: 0, Setting: 69 [info] [client2] REQUEST: 1021 711d17 Lamp | State: 1, Setting: 2 [info] [client2] REQUEST: 1021 443245 Thermostat | State: 2, Setting: 73 [info] [client2] REQUEST: 1022 16fff9 Lamp | State: 0, Setting: 2 [info] [client2] REQUEST: 1022 687826 Lamp | State: 0, Setting: 3 [info] [client2] REQUEST: 1022 2cae5f SecurityAlarm | State: 0, Setting: 1 [info] [client2] REQUEST: 1022 c9e8f9 Thermostat | State: 1, Setting: 69 [info] [client2] REQUEST: 1023 6984f2 Lamp | State: 1, Setting: 2 [info] [client2] REQUEST: 1024 a85495 Thermostat | State: 2, Setting: 72 [info] [client2] RESPONSE: [requester: client2] 1020 2cb5a8 Thermostat | State: 0, Setting: 71 [info] [client2] RESPONSE: [requester: client2] 1020 1a6b0e Lamp | State: 0, Setting: 1 [info] [client2] RESPONSE: [requester: client2] 1020 d1bd73 Thermostat | State: 0, Setting: 61 [info] [client2] RESPONSE: [requester: client2] 1020 5d9f65 Thermostat | State: 2, Setting: 67 [info] [client2] RESPONSE: [requester: client2] 1021 711d17 Lamp | State: 0, Setting: 1 . . . . . . [info] [client2] REQUEST: 1038 a03d22 Thermostat | State: 2, Setting: 68 [info] [client2] RESPONSE: [requester: client2] 1038 c02238 Lamp | State: 1, Setting: 1 [info] [client2] REQUEST: 1038 9e6d4b Thermostat | State: 0, Setting: 72 [info] [client2] RESPONSE: [requester: client2] 1038 a03d22 Thermostat | State: 0, Setting: 67 [info] [client2] REQUEST: 1039 3d7e6d SecurityAlarm | State: 1, Setting: 3 [info] [client2] RESPONSE: [requester: client2] 1038 9e6d4b Thermostat | State: 2, Setting: 74 [info] [client2] RESPONSE: [requester: client2] 1039 3d7e6d SecurityAlarm | State: 1, Setting: 2 [info] [client2] Done IoT states streaming.
What’s next?
In the next blog post, we’ll go over a use case in which the states update request streams from the various clients will be processed by a gRPC dynamic pub/sub service with the response streams broadcast to be consumed by all the participating clients. Source code that includes both use cases will be published in a GitHub repo.