Back in 2013, one of my planned to-do items was to explore the Android programming language. As always, the best way to learn a programming platform is to write code on it. At the time I was hooked on an interesting board game called Alberi (based on some mathematical puzzle designed by Giorgio Dendi), so I decided to develop a board game using the very game logic as a programming exercise. I was going to post it in a blog but was buried in a different project upon finishing the code.
This was the first Android application I’ve ever developed. It turned out to be a little more complex than initially thought as a first programming exercise on a platform unfamiliar to me. Nevertheless, it was fun to develop a game I enjoyed playing. Android is Java-based so to me the learning curve is not that steep, and the Android SDK comes with a lot of sample code that can be borrowed.
The game is pretty simple. For a given game, the square-shaped board is composed of N rows x N columns of square cells. The entire board is also divided into N contiguous colored zones. The goal is to distribute a number of treasure chests over the board with the following rules:
- Each row must have 1 treasure chest
- Each column must have 1 treasure chest
- Each zone must have 1 treasure chest
- Treasure chests cannot be adjacent row-wise, column-wise or diagonally to each other
- There is also a variant of 2 treasure chests (per row/column/zone) at larger board size
Here’s a screen-shot of the board game (N = 6):
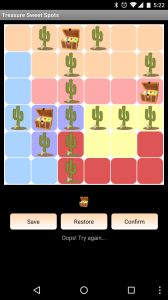
SweetSpots screenshot
Publishing the game app on Google Play
Back then I didn’t publish the game on Google Play. I’ve decided to do it now just to try out the process. To do that, I need to create a signed Android application package (APK) then zip-align it as per Google’s publish requirement. Eclipse and Android SDK along with Android Debug Bridge (adb) for the Android device simulator were used for developing the app back in 2013. Android OS version at the time was Jelly Bean, although the game still plays fine today on my Lollipop Android phone. The Eclipse version used for the development was Juno and Android SDK version was 17.0.0.
Just two years later today, while the game app still runs fine as an unsigned APK on the current Android platform it no longer builds properly on the latest Eclipse (Mars) and Android SDK (v24.0.2), giving the infamous “R cannot be resolved” error. Lots of suggestions out there on how to solve the problem such as fixing the resource XML, modifying build path, etc, but unfortunately none applies.
As Google is ending support for Android Developer Tool (ADT) in Eclipse literally by end of the month, leaving IntelliJ-based Android Studio the de facto IDE for future Android app development, I thought I would give it a shot. Android Studio appears to be a great IDE product and importing the Eclipse project to it was effortless. It even nicely correlates dependencies and organizes multiple related projects into one. But then a stubborn adb connection problem blocked me from moving forward. I decided to move back to Eclipse. Finally, after experimenting and mixing the Android SDK build tools and platform tools with older versions I managed to successfully build the app. Here’s the published game at Google Play.
From Tic-tac-toe to SweetSpots
The Android’s SDK version I used comes with a bunch of sample applications along with working code. Among the applications is a Tic-tac-toe game which I decided would serve well as the codebase for the board game. I gave the game a name called Sweet Spots.
Following the code structure of the Tic-tac-toe sample application, there are two inter-dependent projects for Sweet Spots: SweetSpotsMain and SweetSpotsLib, each with its own manifest file (AndroidManifest.xml). The file system structure of the source code and resource files is simple:
/path-to-app/SweetSpotsMain/
AndroidManifest.xml
res/
drawable/
icon.png
layout/
main.xml
layout-land/
main.xml
values/
strings.xml
src/
com/
genuine/
android/
sweetspots/
MainActivity.java
/path-to-app/SweetSpotsLib/
AndroidManifest.xml
res/
drawable/
(board content images)
layout/
lib_game.xml
layout-land/
lib_game.xml
values/
strings.xml
src/
com/
genuine/
android/
sweetspots/
library/
GameActivity.java
GameView.java
MainActivity (extends Activity)
The main Java class in SweetSpotsMain is MainActivity, which defines method onCreate() that consists of buttons for games of various board sizes. In the original code repurposed from the Tic-tac-toe app, each of the game buttons uses its own onClickListener that defines onClick(), which in turn calls startGame() to launch GameActivity using startActivity() by means of an Intent object with the GameActivity class. It has been refactored to have the activity class implement onClickListener and override onCreate() with setOnClickListener(this) and onClick() with specific actions for individual buttons.
View source code of MainActivity.java in a separate browser tab.
GameActivity (extends Activity)
One of the main Java classes in SweetSpotsLib is GameActivity. It defines a few standard activities including onCreate(), onPause() and onResume(). GameActivity also implements a number of onClickListener’s for operational buttons such as Save, Restore and Confirm. The Save and Restore buttons are for temporarily saving the current game state to be restored, say, after trying a few tentative moves. Clicking on the Confirm button will initiate validation of the game rules.
View source code of GameActivity.java in a separate browser tab.
GameView (extends View)
The other main Java class in SweetSpotsLib is GameView, which defines and maintains the view of the board game in accordance with the activities. It defines many of the game-logic methods within standard method calls including onDraw(), onMeasure(), onSizeChanged(), onTouchEvent(), onSaveInstanceState() and onRestoreInstanceState().
GameView also consists of interface ICellListener with the abstract method onCellSelected() that is implemented in GameActivity. The method does nothing in GameActivity but could be added with control logic if wanted.
View source code of GameView.java in a separate browser tab.
Resource files
Images and layout (portrait/landscape) are stored under the res/ subdirectory. Much of the key parametric data (e.g. board size) is also stored there in res/values/strings.xml. Since this was primarily a programming exercise on a mobile platform, visual design/UI wasn’t given much effort. Images used in the board game were assembled using Gimp from public domain sources.
Complete source code for the Android board game is at: https://github.com/oel/sweetspots
How were the games created?
These games were created using a separate Java application that, for each game, automatically generates random zones on the board and validate the game via trial-and-error for a solution. I’ll talk about the application in a separate blog post when I find time. One caveat about the automatic game solution creation is that the solution is generally not unique. A game with unique solution would allow some interesting game-playing logic to be more effective in solving the game. One way to create a unique solution would be to manually re-shape the zones in the generated solution.