While blockchain has been steadily gaining increasing attention from the general public over the past couple of years, it’s NFT, short for non-fungible token, that has recently taken the center stage. In particular, NFT shines in the area of provenance of authenticity. By programmatically binding a given asset to a unique digital token referencing immutable associated transactions on a blockchain, the NFT essentially serves as the “digital receipt” of the asset.
Currently Ethereum is undergoing a major upgrade to cope with future growth of the blockchain platform which has been suffering from low transaction rate and high gas fee due to the existing unscalable Proof of Work consensus algorithm. As described in a previous blockchain overview blog post, off-chain solutions including bridging the Ethereum main chain with layer-2 subchains such as Polygon help circumvent the performance issue.
Avalanche
Some layer-1 blockchains support Ethereum’s NFT standards (e.g. ERC-721, ERC-1155) in addition to providing their own native NFT specs. Among them is Avalanche which has been steadily growing its market share (in terms of TVL), trailing behind only a couple of prominent layer-1 blockchains such as Solana and Cardano.
With separation of concerns (SoC) being one of the underlying design principles, Avalanche uses a subnet model in which validators on the subnet only operate on the specific blockchains of their interest Also in line with the SoC design principle, Avalanche comes with 3 built-in blockchains each of which serves specific purposes with its own set of API:
- Exchange Chain (X-Chain) – for creation & exchange of digital smart assets (including its native token AVAX) which are bound to programmatic governance rules
- Platform Chain (P-Chain) – for creating & tracking
subnets, each comprising a dynamic group of stake holders responsible for consensually validating blockchains of interest - Contract Chain (C-Chain) – for developing smart contract applications
NFT on Avalanche
Avalanche allows creation of native NFTs as a kind of its smart digital assets. Its website provides tutorials for creating such NFTs using its Go-based AvalancheGo API. But perhaps its support of the Ethereum-compatible NFT standards with much higher transaction rate and lower cost than the existing Ethereum mainnet is what helps popularize the platform.
In this blog post, we’re going to create on the Avalanche platform ERC-721 compliant NFTs which require programmatic implementation of their sale/transfer terms in smart contracts. C-Chain is therefore the targeted blockchain. And rather than deploying our NFTs on the Avalanche mainnet, we’ll use the Avalanche Fuji Testnet which allows developers to pay for transactions in test-only AVAX tokens freely available from some designated crypto faucet.
Scaffold-ETH: an Ethereum development stack
A code repository of comprehensive Ethereum-based blockchain computing functions, Scaffold-ETH, offers a suite of tech stacks best for fast prototyping development along with sample code for various use cases of decentralized applications. The stacks include Solidity, Hardhat, Ether.js and ReactJS.
The following softwares are required for installing Scaffold-ETH, building and deploying NFT smart contracts:
Launching NFTs on Avalanche using a customized Scaffold-ETH
For the impatient, the revised code repo is at this GitHub link. Key changes made to the original branch in Scaffold-ETH will be highlighted at the bottom of this post.
To get a copy of Scaffold-ETH repurposed for NFTs on Avalanche, first git-clone the repo:
git clone https://github.com/oel/avalanche-scaffold-eth-nft avax-scaffold-eth-nft
Next, open up a couple of shell command terminals and navigate to the project-root (e.g. avax-scaffold-eth-nft).
Step 1: From the 1st shell terminal, install the necessary dependent modules.
cd avax-scaffold-eth-nft/ yarn install
Step 2: From the 2nd terminal, specify an account as the deployer.
Choose an account that owns some AVAX tokens (otherwise, get free tokens from an AVAX faucet) on the Avalanche Fuji testnet and create file packages/hardhat/mnemonic.txt with the account’s 12-word mnemonic in it.
cd avax-scaffold-eth-nft/ yarn account yarn deploy --network fujiAvalanche
For future references, the “deployed at” smart contract address should be saved. Transactions oriented around the smart contract can be reviewed at snowtrace.io.
Step 3: Back to the 1st terminal, start the Node.js server at port# 3000.
yarn start
This will spawn a web page on the default browser (which should have been installed with the MetaMask extension).
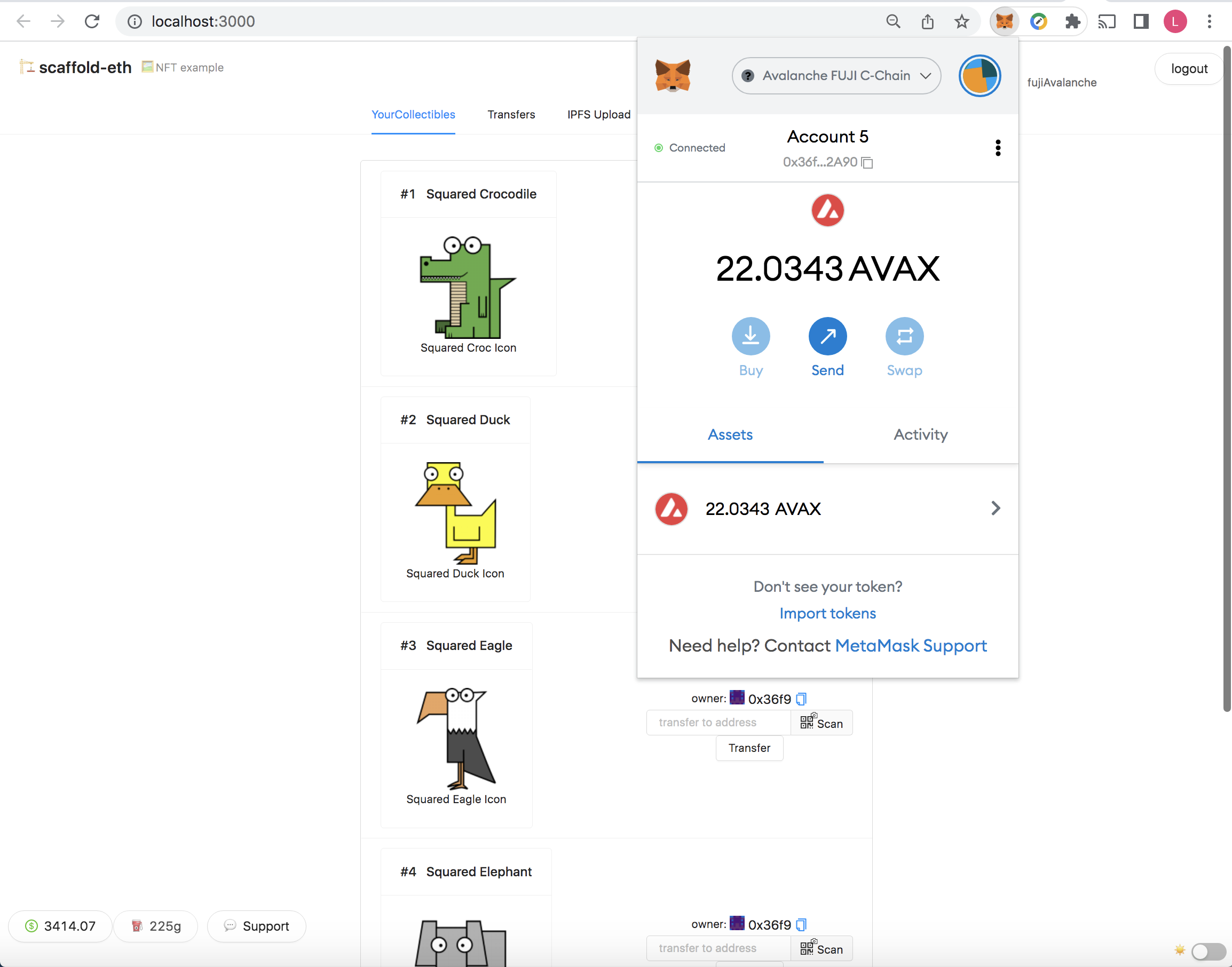
Step 4: From the web browser, connect to the MetaMask account which will receive the NFTs
Step 5: Back to the 2nd terminal, mint the NFTs.
yarn mint --network fujiAvalanche
The address of the NFT recipient account connected to the browser app will be prompted. Upon successful minting, images of the NFTs should be automatically displayed on the web page.
To transfer any of the NFTs to another account, enter the address of the account to be transferred to and click “transfer”. Note that the account connected to the browser app would need to own some AVAX tokens (again if not, get free tokens from an AVAX faucet).
The web page upon successful minting should look like below:
Key changes made to the original Scaffold-ETH branch
It should be noted that Scaffold-ETH is a popular code repo under active development. The branch I had experimented with a few months ago is already markedly different from the same branch I git-cloned for custom modification. That prompted me to clone a separate repo to serve as a “snapshot” of the branch, rather than just showing my modifications to an evolving code base.
Below are the main changes made to the Scaffold-ETH Simple NFT Example branch git-cloned on March 30:
Hardhat configuration script: packages/hardhat/hardhat.config.js
The defaultNetwork value in the original Hardhat configuration script is “localhost” by default, assuming a local instance of a selected blockchain is in place. The following change sets the default network to the Fuji testnet, whose network configuration parameters need to be added as shown below.
const defaultNetwork = "fujiAvalanche";
# const defaultNetwork = "mainnetAvalanche";
...
module.exports = {
...
networks: {
...
fujiAvalanche: {
url: "https://api.avax-test.network/ext/bc/C/rpc",
gasPrice: 225000000000,
chainId: 43113,
accounts: {
mnemonic: mnemonic(),
},
},
...
Note that with the explicit defaultNetwork value set to “fujiAvalanche”, one could skip the --network fujiAvalanche command line option in the smart contract deploy and mint commands.
ReactJS main app: packages/react-app/src/App.jsx
To avoid compilation error, the following imports need to be moved up above the variable declaration section in main Node.js app.
import { useContractConfig } from "./hooks"
import Portis from "@portis/web3";
import Fortmatic from "fortmatic";
import Authereum from "authereum";
...
const targetNetwork = NETWORKS.fujiAvalanche;
# const targetNetwork = NETWORKS.mainnetAvalanche
Minting script: packages/hardhat/scripts/mint.js
A few notes:
- The square-shaped animal icon images for the NFTs used in the minting script are from public domain sources. Here’s the link to the author’s website.
- Node module
prompt-syncis being used (thus is also added to the mainpackage.jsondependency list). It’s to avoid having to hardcode the NFT recipient address in the minting script. - The code below makes variable
toAddressa dynamic input value and replaces the original NFT images with the square-styling images along with a modularizedmintItemfunction.
...
const prompt = require('prompt-sync')();
const delayMS = 5000 // Increase delay as needed!
const main = async () => {
// ADDRESS TO MINT TO:
// const toAddress = "0x36f90A958f94F77c26614DB170a5C8a7DF062A90"
const toAddress = prompt("Enter the address to mint to: ");
console.log("\n\n 🎫 Minting to "+toAddress+"...\n");
const { deployer } = await getNamedAccounts();
const yourCollectible = await ethers.getContract("YourCollectible", deployer);
// Item #1
const iconCrocodile = {
"description": "Squared Croc Icon",
"external_url": "https://blog.genuine.com/",
"image": "https://blog.genuine.com/wp-content/uploads/2022/03/Crocodile-icon.png",
"name": "Squared Crocodile",
"attributes": [
{
"trait_type": "Color",
"value": "Green"
}
]
}
mintItem(iconCrocodile, yourCollectible, toAddress)
await sleep(delayMS)
// Item #2
const iconDuck = {
"description": "Squared Duck Icon",
"external_url": "https://blog.genuine.com/",
"image": "https://blog.genuine.com/wp-content/uploads/2022/03/Duck-icon.png",
"name": "Squared Duck",
"attributes": [
{
"trait_type": "Color",
"value": "Yellow"
}
]
}
mintItem(iconDuck, yourCollectible, toAddress)
await sleep(delayMS)
// Item #3
const iconEagle = {
"description": "Squared Eagle Icon",
"external_url": "https://blog.genuine.com/",
"image": "https://blog.genuine.com/wp-content/uploads/2022/03/Eagle-icon.png",
"name": "Squared Eagle",
"attributes": [
{
"trait_type": "Color",
"value": "Dark Gray"
}
]
}
mintItem(iconEagle, yourCollectible, toAddress)
await sleep(delayMS)
// Item #4
const iconElephant = {
"description": "Squared Elephant Icon",
"external_url": "https://blog.genuine.com/",
"image": "https://blog.genuine.com/wp-content/uploads/2022/03/Elephant-icon.png",
"name": "Squared Elephant",
"attributes": [
{
"trait_type": "Color",
"value": "Light Gray"
}
]
}
mintItem(iconElephant, yourCollectible, toAddress)
await sleep(delayMS)
// Item #5
const iconFish = {
"description": "Squared Fish Icon",
"external_url": "https://blog.genuine.com/",
"image": "https://blog.genuine.com/wp-content/uploads/2022/03/Fish-icon.png",
"name": "Squared Fish",
"attributes": [
{
"trait_type": "Color",
"value": "Blue"
}
]
}
mintItem(iconFish, yourCollectible, toAddress)
await sleep(delayMS)
console.log("Transferring Ownership of YourCollectible to "+toAddress+"...")
await yourCollectible.transferOwnership(toAddress, { gasLimit: 8000000 }); // Increase limit as needed!
await sleep(delayMS)
...
}
async function mintItem(item, contract, mintTo, limit = 8000000) { // Increase limit as needed!
console.log("Uploading `%s` ...", item.name)
const uploaded = await ipfs.add(JSON.stringify(item))
console.log("Minting `%s` with IPFS hash ("+uploaded.path+") ...", item.name)
await contract.mintItem(mintTo,uploaded.path,{gasLimit:limit})
}
...