
With the increasing demand for big data transformations on distributed platforms, one approach is to put in place a streaming ETL system with built-in packpressure using Alpakka Kafka API that allows composable pipelines to be constructed on-demand. This blog post extends the previous post which shows a skeletal version of the system.
Let’s first review the diagram shown in the previous post of what we’re aiming to build — a streaming ETL system empowered by reactive streams and Apache Kafka’s publish-subscribe machinery for durable stream data to be produced or consumed by various data processing/storage systems:
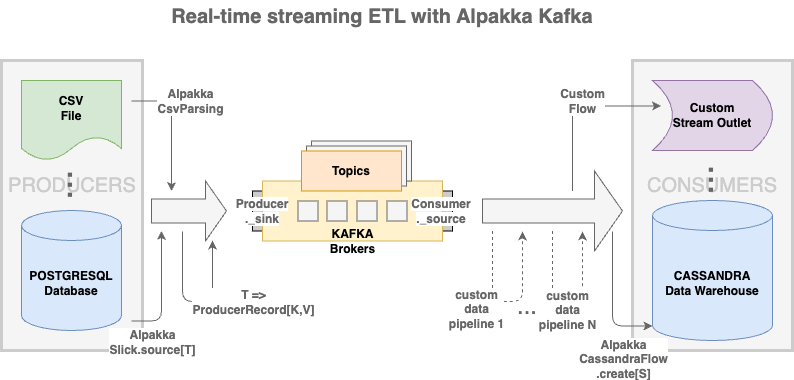
In this blog post, we’re going to:
- enhance the data warehouse consumer to programmatically track the
commitoffset positions, - plug into an existing consumer a data processing pipeline as a stream processing operator, and,
- add to the streaming ETL system a mix of heterogeneous producers and consumers
Action item #1 would address the requirement of at-least-once delivery in stream consumption. #2 illustrates how to add to the streaming ETL system a custom data pipeline as a composable stream flow, and #3 showcases how data in various storage systems can participate in the real-time stream to operate (serially or in parallel) as composable sources, flows and sinks. All relevant source code is available in this GitHub repo.
Real-time streaming ETL/pipelining of property listing data
For usage demonstration, the application runs ETL/pipelining of data with a minified real estate property listing data model. It should be noted that expanding or even changing it altogether to a different data model should not affect how the core streaming ETL system operates.
Below are a couple of links related to library dependencies and configurations for the core application:
- Library dependencies in build.sbt [separate tab]
- Configurations for Akka, Kafka, PostgreSQL & Cassandra in application.conf [separate tab]
It’s also worth noting that the application can be scaled up with just configurative changes. For example, if the Kafka brokers and Cassandra database span across multiple hosts, relevant configurations like Kafka’s bootstrap.servers could be "10.1.0.1:9092,10.1.0.2:9092,10.1.0.3:9092" and contact-points for Cassandra might look like ["10.2.0.1:9042","10.2.0.2:9042"].
Next, let’s get ourselves familiarized with the property listing data definitions in the PostgreSQL and Cassandra, as well as the property listing classes that model the schemas.
- schema_postgresql.script.txt [separate tab]
- schema_cassandra.script.txt [separate tab]
- PropertyListing.scala [separate tab]
A Kafka producer using Alpakka Csv
Alpakka comes with a simple API for CSV file parsing with method lineScanner() that takes parameters including the delimiter character and returns a Flow[ByteString, List[ByteString], NotUsed].
Below is the relevant code in CsvPlain.scala that highlights how the CSV file gets parsed and materialized into a stream of Map[String,String] via CsvParsing and CsvToMap, followed by transforming into a stream of PropertyListing objects.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
val source: Source[PropertyListing, NotUsed] = FileIO.fromPath(Paths.get(csvFilePath)) .via(CsvParsing.lineScanner(CsvParsing.Tab)) .viaMat(CsvToMap.toMapAsStrings())(Keep.right) .drop(offset).take(limit) .map(toClassPropertyListing(_)) // ... source .map{ property => val prodRec = new ProducerRecord[String, String]( topic, property.propertyId.toString, property.toJson.compactPrint ) println(s"[CSV] >>> Producer msg: $prodRec") prodRec } .runWith(Producer.plainSink(producerSettings)) |
Note that the drop(offset)/take(limit) code line, which can be useful for testing, is for taking a segmented range of the stream source and can be removed if preferred.
A subsequent map wraps each of the PropertyListing objects in a ProducerRecord[K,V] with the associated topic and key/value of type String/JSON before being streamed into Kafka via Alpakka Kafka’s Producer.plainSink().
A Kafka producer using Alpakka Slick
The PostgresPlain producer, which is pretty much identical to the one described in the previous blog post, creates a Kafka producer using Alpakka Slick which allows SQL queries into a PostgreSQL database to be coded in Slick’s functional programming style.
The partial code below shows how method Slick.source() takes a streaming query and returns a stream source of PropertyListing objects.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
val source: Source[PropertyListing, NotUsed] = Slick .source(TableQuery[PropertyListings].sortBy(_.propertyId).drop(offset).take(limit).result) // ... source .map{ property => val prodRec = new ProducerRecord[String, String]( topic, property.propertyId.toString, property.toJson.compactPrint ) println(s"[POSTRES] >>> Producer msg: $prodRec") prodRec } .runWith(Producer.plainSink(producerSettings)) |
The high-level code logic in PostgresPlain is similar to that of the CsvPlain producer.
A Kafka consumer using Alpakka Cassandra
We created a Kafka consumer in the previous blog post using Alpakka Kafka’s Consumer.plainSource[K,V] for consuming data from a given Kafka topic into a Cassandra database.
The following partial code from the slightly refactored version of the consumer, CassandraPlain shows how data associated with a given Kafka topic can be consumed via Alpakka Kafka’s Consumer.plainSource().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
def runPropertyListing(consumerGroup: String, topic: String)(implicit cassandraSession: CassandraSession, jsonFormat: JsonFormat[PropertyListing], system: ActorSystem, ec: ExecutionContext): Future[Done] = { val consumerConfig = system.settings.config.getConfig("akkafka.consumer.with-brokers") val consumerSettings = ConsumerSettings(consumerConfig, new StringDeserializer, new StringDeserializer) .withGroupId(consumerGroup) .withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest") val table = "propertydata.property_listing" val partitions = 10 // number of partitions val statementBinder: (ConsumerRecord[String, String], PreparedStatement) => BoundStatement = { case (msg, preparedStatement) => val p = msg.value().parseJson.convertTo[PropertyListing] preparedStatement.bind( (p.propertyId % partitions).toString, Int.box(p.propertyId), p.dataSource.getOrElse("unknown"), Double.box(p.bathrooms.getOrElse(0)), Int.box(p.bedrooms.getOrElse(0)), Double.box(p.listPrice.getOrElse(0)), Int.box(p.livingArea.getOrElse(0)), p.propertyType.getOrElse(""), p.yearBuilt.getOrElse(""), p.lastUpdated.getOrElse(""), p.streetAddress.getOrElse(""), p.city.getOrElse(""), p.state.getOrElse(""), p.zip.getOrElse(""), p.country.getOrElse("") ) } val cassandraFlow: Flow[ConsumerRecord[String, String], ConsumerRecord[String, String], NotUsed] = CassandraFlow.create( CassandraWriteSettings.defaults, s"""INSERT INTO $table (partition_key, property_id, data_source, bathrooms, bedrooms, list_price, living_area, property_type, year_built, last_updated, street_address, city, state, zip, country) |VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)""".stripMargin, statementBinder ) val control: DrainingControl[Done] = Consumer .plainSource(consumerSettings, Subscriptions.topics(topic)) .via(cassandraFlow) .toMat(Sink.ignore)(DrainingControl.apply) .run() Thread.sleep(2000) control.drainAndShutdown() } |
Alpakka’s CassandraFlow.create() is the stream processing operator responsible for funneling data into the Cassandra database. Note that it takes a CQL PreparedStatement along with a “statement binder” that binds the incoming class variables to the corresponding Cassandra table columns before executing the CQL.
Enhancing the Kafka consumer for ‘at-least-once’ consumption
To enable at-least-once consumption by Cassandra, instead of Consumer.plainSource[K,V], we construct the stream graph via Alpakka Kafka Consumer.committableSource[K,V] which offers programmatic tracking of the commit offset positions. By keeping the commit offsets as an integral part of the streaming data, failed streams could be re-run from the offset positions.
The main stream composition code of the enhanced consumer, CassandraCommittable.scala, is shown below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
def runPropertyListing(consumerGroup: String, topic: String)(implicit cassandraSession: CassandraSession, jsonFormat: JsonFormat[PropertyListing], system: ActorSystem, ec: ExecutionContext): Future[Done] = { val consumerConfig = system.settings.config.getConfig("akkafka.consumer.with-brokers") val consumerSettings = ConsumerSettings(consumerConfig, new StringDeserializer, new StringDeserializer) .withGroupId(consumerGroup) .withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest") val committerConfig = system.settings.config.getConfig("akka.kafka.committer") val committerSettings = CommitterSettings(committerConfig) val table = "propertydata.property_listing" val partitions = 10 // number of partitions val statementBinder: (CommittableMessage[String, String], PreparedStatement) => BoundStatement = { case (msg, preparedStatement) => val p = msg.record.value().parseJson.convertTo[PropertyListing] preparedStatement.bind( (p.propertyId % partitions).toString, Int.box(p.propertyId), p.dataSource.getOrElse("unknown"), Double.box(p.bathrooms.getOrElse(0)), Int.box(p.bedrooms.getOrElse(0)), Double.box(p.listPrice.getOrElse(0)), Int.box(p.livingArea.getOrElse(0)), p.propertyType.getOrElse(""), p.yearBuilt.getOrElse(""), p.lastUpdated.getOrElse(""), p.streetAddress.getOrElse(""), p.city.getOrElse(""), p.state.getOrElse(""), p.zip.getOrElse(""), p.country.getOrElse("") ) } val cassandraFlow: Flow[CommittableMessage[String, String], CommittableMessage[String, String], NotUsed] = CassandraFlow.create( CassandraWriteSettings.defaults, s"""INSERT INTO $table (partition_key, property_id, data_source, bathrooms, bedrooms, list_price, living_area, property_type, year_built, last_updated, street_address, city, state, zip, country) |VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)""".stripMargin, statementBinder ) val control = Consumer .committableSource(consumerSettings, Subscriptions.topics(topic)) .via(cassandraFlow) .map(_.committableOffset) .toMat(Committer.sink(committerSettings))(DrainingControl.apply) .run() Thread.sleep(2000) control.drainAndShutdown() } |
A couple of notes:
- In order to be able to programmatically keep track of the commit offset positions, each of the stream elements emitted from
Consumer.committableSource[K,V]is wrapped in a CommittableMessage[K,V] object, consisting of theCommittableOffsetvalue in addition to the Kafka ConsumerRecord[K,V]. - Committing the offset should be done after the stream data is processed for at-least-once consumption, whereas committing prior to processing the stream data would only achieve at-most-once delivery.
Adding a property-rating pipeline to the Alpakka Kafka consumer
Next, we add a data processing pipeline to the consumer to perform a number of ratings of the individual property listings in the stream before delivering the rated property listing data to the Cassandra database, as illustrated in the following diagram.
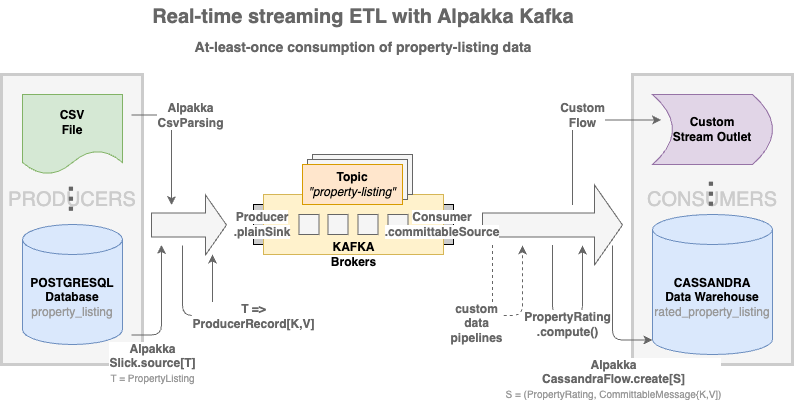
Since the CassandraFlow.create() stream operator will be executed after the rating pipeline, the corresponding “statement binder” necessary for class-variable/table-column binding will now need to encapsulate also PropertyRating along with CommittableMessage[K,V], as shown in the partial code of CassandraCommittableWithRatings.scala below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
def runPropertyListing(consumerGroup: String, topic: String)(implicit cassandraSession: CassandraSession, jsonFormat: JsonFormat[PropertyListing], system: ActorSystem, ec: ExecutionContext): Future[Done] = { val consumerConfig = system.settings.config.getConfig("akkafka.consumer.with-brokers") val consumerSettings = ConsumerSettings(consumerConfig, new StringDeserializer, new StringDeserializer) .withGroupId(consumerGroup) .withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest") val committerConfig = system.settings.config.getConfig("akka.kafka.committer") val committerSettings = CommitterSettings(committerConfig) val table = "propertydata.rated_property_listing" val partitions = 10 // number of partitions val statementBinder: ((PropertyRating, CommittableMessage[String, String]), PreparedStatement) => BoundStatement = { case ((rating, msg), preparedStatement) => val p = msg.record.value().parseJson.convertTo[PropertyListing] preparedStatement.bind( (p.propertyId % partitions).toString, Int.box(p.propertyId), p.dataSource.getOrElse("unknown"), Double.box(p.bathrooms.getOrElse(0)), Int.box(p.bedrooms.getOrElse(0)), Double.box(p.listPrice.getOrElse(0)), Int.box(p.livingArea.getOrElse(0)), p.propertyType.getOrElse(""), p.yearBuilt.getOrElse(""), p.lastUpdated.getOrElse(""), p.streetAddress.getOrElse(""), p.city.getOrElse(""), p.state.getOrElse(""), p.zip.getOrElse(""), p.country.getOrElse(""), rating.affordability.getOrElse(0), rating.comfort.getOrElse(0), rating.neighborhood.getOrElse(0), rating.schools.getOrElse(0) ) } val cassandraFlow: Flow[(PropertyRating, CommittableMessage[String, String]), (PropertyRating, CommittableMessage[String, String]), NotUsed] = CassandraFlow.create( CassandraWriteSettings.defaults, s"""INSERT INTO $table (partition_key, property_id, data_source, bathrooms, bedrooms, list_price, living_area, property_type, year_built, last_updated, street_address, city, state, zip, country, rating_affordability, rating_comfort, rating_neighborhood, rating_schools) |VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)""".stripMargin, statementBinder ) val control = Consumer .committableSource(consumerSettings, Subscriptions.topics(topic)) .via(PropertyRating.compute()) .via(cassandraFlow) .map { case (_, msg) => msg.committableOffset } .toMat(Committer.sink(committerSettings))(DrainingControl.apply) .run() Thread.sleep(2000) control.drainAndShutdown() } |
For demonstration purpose, we create a dummy pipeline for rating of individual real estate properties in areas such as affordability, neighborhood, each returning just a Future of random integers between 1 and 5 after a random time delay. The rating related fields along with the computation logic are wrapped in class PropertyRating as shown below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
case class PropertyRating( propertyId: Int, affordability: Option[Int], comfort: Option[Int], neighborhood: Option[Int], schools: Option[Int] ) object PropertyRating { def rand = java.util.concurrent.ThreadLocalRandom.current def biasedRandNum(l: Int, u: Int, biasedNums: Set[Int], biasedFactor: Int = 1): Int = { Vector .iterate(rand.nextInt(l, u+1), biasedFactor)(_ => rand.nextInt(l, u+1)) .dropWhile(!biasedNums.contains(_)) .headOption match { case Some(n) => n case None => rand.nextInt(l, u+1) } } def fakeRating()(implicit ec: ExecutionContext): Future[Int] = Future{ // Fake rating computation Thread.sleep(biasedRandNum(1, 9, Set(3, 4, 5))) // Sleep 1-9 secs biasedRandNum(1, 5, Set(2, 3, 4)) // Rating 1-5; mostly 2-4 } def compute()(implicit ec: ExecutionContext): Flow[CommittableMessage[String, String], (PropertyRating, CommittableMessage[String, String]), NotUsed] = Flow[CommittableMessage[String, String]].mapAsync(1){ msg => val propertyId = msg.record.key().toInt // let it crash in case of bad PK data ( for { affordability <- PropertyRating.fakeRating() comfort <- PropertyRating.fakeRating() neighborhood <- PropertyRating.fakeRating() schools <- PropertyRating.fakeRating() } yield new PropertyRating(propertyId, Option(affordability), Option(comfort), Option(neighborhood), Option(schools)) ) .map(rating => (rating, msg)).recover{ case e => throw new Exception("ERROR in computeRatingFlow()!") } } } |
A Kafka consumer with a custom flow & stream destination
The application is also bundled with a consumer with the property rating pipeline followed by a custom flow to showcase how one can compose an arbitrary side-effecting operator with custom stream destination.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
def customBusinessLogic(key: String, value: String, rating: PropertyRating)( implicit ec: ExecutionContext): Future[Done] = Future { println(s"KEY: $key VALUE: $value RATING: $rating") // Perform custom business logic with key/value // and save to an external storage, etc. Done } def runPropertyListing(consumerGroup: String, topic: String)(implicit jsonFormat: JsonFormat[PropertyListing], system: ActorSystem, ec: ExecutionContext): Future[Done] = { val consumerConfig = system.settings.config.getConfig("akkafka.consumer.with-brokers") val consumerSettings = ConsumerSettings(consumerConfig, new StringDeserializer, new StringDeserializer) .withGroupId(consumerGroup) .withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest") val committerConfig = system.settings.config.getConfig("akka.kafka.committer") val committerSettings = CommitterSettings(committerConfig) val control = Consumer .committableSource(consumerSettings, Subscriptions.topics(topic)) .via(PropertyRating.compute()) .mapAsync(1) { case (rating, msg) => customBusinessLogic(msg.record.key, msg.record.value, rating) .map(_ => msg.committableOffset) } .toMat(Committer.sink(committerSettings))(DrainingControl.apply) .run() Thread.sleep(5000) control.drainAndShutdown() } |
Note that mapAsync is used to allow the stream transformation by the custom business logic to be carried out asynchronously.
Running the streaming ETL/pipelining system
To run the application that comes with sample real estate property listing data on a computer, go to the GitHub repo and follow the README instructions to launch the producers and consumers on one or more command-line terminals.
Also included in the README are instructions about how to run a couple of set queries to verify data that get ETL-ed to the Cassandra tables via Alpakka Cassandra’s CassandraSource which takes a CQL query as its argument.
Further enhancements
Depending on specific business requirement, the streaming ETL system can be further enhanced in a number of areas.
- This streaming ETL system offers at-least-once delivery only in stream consumptions. If an end-to-end version is necessary, one could enhance the producers by using Producer.committabbleSink() or Producer.flexiFlow() instead of
Producer.plainSink(). - For exactly-once delivery, which is a generally much more stringent requirement, one approach to achieve that would be to atomically persist the in-flight data with the corresponding commit offset positions using a reliable storage system.
- In case tracking of Kafka’s topic partition assignment is required, one can use Consumer.committablePartitionedSource[K,V] instead of
Consumer.committableSource[K,V]. More details can be found in the tech doc. - To gracefully restart a stream on failure with a configurable backoff, Akka Stream provides method RestartSource.onFailuresWithBackoff for that as illustrated in an example in this tech doc.