As proposed at the beginning of this blockchain mini blog series, we’ll have an Actor-based blockchain application at the end of the series. The fully functional application is written in Scala along with the Akka toolkit.
While this is part of a blog series, this post could still be viewed as an independent one that illustrates the functional flow of a blockchain application implemented in Scala/Akka.
What is a blockchain?
Summarizing a few key characteristics of a blockchain (primarily from the angle of a cryptocurrency system):
- At the core of a cryptocurrency system is a distributed ledger with a collection of transactions stored in individual “blocks” each of which is successively chained to another, thus the term “blockchain”.
- There is no centralized database storing the ledger as the authoritative data source. Instead, each of the decentralized “nodes” maintains its own copy of the blockchain that gets updated in a consensual fashion.
- At the heart of the so-called “mining” process lies a “consensus” algorithm that determines how participants can earn the mining reward as an incentive for them to collaboratively grow the blockchain.
- One of the most popular consensus algorithms is Proof of Work (PoW), which is a computationally demanding task for the “miners” to compete for a reward (i.e. a certain amount of digital coins) offered by the system upon successfully adding a new block to the existing blockchain.
- In a cryptocurrency system like Bitcoin, the blockchain that has the highest PoW value (generally measured by the
length, or technically referred to asheight) of the blockchain overrides the rest.
Beyond cryptocurrency
While blockchain is commonly associated with cryptocurrency, the term has been generalized to become a computing class (namely blockchain computing) covering a wide range of use cases, such as supply chain management, asset tokenization. For instance, Ethereum, a prominent cryptocurrency, is also a increasingly popular computing platform for building blockchain-based decentralized applications. Its codebase is primarily in Golang and C++.
Within the Ethereum ecosystem, Truffle (a development environment for decentralized applications) and Solidity (a JavaScript alike scripting language for developing “smart contracts”), among others, have prospered and attracted many programmers from different industry sectors to develop decentralized applications on the platform.
In the Scala world, there is a blockchain framework, Scorex 2.0 that allows one to build blockchain applications not limited to cryptocurrency systems. Supporting multiple kinds of consensus algorithms, it offers a versatile framework for developing custom blockchain applications. Its predecessor, Scorex, is what powers the Waves blockchain. As of this post, the framework is still largely in experimental stage though.
How Akka Actors fit into running a blockchain system
A predominant implementation of the Actor model, Akka Actors offer a comprehensive API for building scalable distributed systems such as Internet-of-Things (IoT) systems. It comes as no surprise the toolset also works great for what a blockchain application requires.
Lightweight and loosely-coupled by design, actors can serve as an efficient construct to model the behaviors of the blockchain mining activities that involve autonomous block creations in parallel using a consensus algorithm on multiple nodes. In addition, the non-blocking interactions among actors via message passing (i.e. the fire-and-forget tell or query-alike ask methods) allow individual modules to effectively interact with custom logic flow or share states with each other. The versatile interaction functionality makes actors useful for building various kinds of modules from highly interactive routines such as simulation of transaction bookkeeping to request/response queries like blockchain validation.
On distributed cluster functionality, Akka provides a suite of cluster features — cluster-wide routing, distributed data replication, cluster sharding, distributed publish/subscribe, etc. There are different approaches to maintaining the decentralized blockchains on individual cluster nodes. For multiple independent mining processes to consensually share with each others their latest blockchains in a decentralized fashion, Akka’s distributed pub/sub proves to be a superb tool.
A blockchain application that mimics a simplified cryptocurrency system
UPDATE: A new version of this application that uses Akka Typed actors (as opposed to the Akka classic actors) is available. An overview of the new application is at this blog post. Also available is a mini blog series that describes the basic how-to’s for migrating from Akka classic to Akka Typed.
It should be noted that Akka Actors has started moving towards Typed Actors since release 2.5, although both classic and typed actors are being supported in the current 2.6 release. While the Akka Typed API which enforces type-safe code is now a stable release, it’s still relatively new and the API change is rather drastic, requiring experimental effort to ensure everything does what it advertises. Partly because of that, Akka classic actors are used in this blockchain application. Nonetheless, the code should run fine on both Akka 2.5 and 2.6.
Build tool for the application is the good old sbt, with the library dependencies specified in built.sbt and all the configurative values of the Akka cluster and blockchain specifics such as the proof-of-work difficulty level, mining reward, time-out settings in application.conf:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
akka { actor { provider = "cluster" default-dispatcher { throughput = 10 } allow-java-serialization = on warn-about-java-serializer-usage = off } remote.artery { enabled = on transport = tcp canonical { hostname = "127.0.0.1" port = 2551 } } cluster { seed-nodes = [ "akka://blockchain@127.0.0.1:2551", "akka://blockchain@127.0.0.1:2552" ] } } blockchain { proof-of-work { difficulty = 3 nonce = 0 reward = 99 network-name = "akka-blockchain" network-account-key = "MIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEApKyCqvNjx+YfVYFippxviV0UgEgpYJbV0luEJTkcbnvIIolqXR5JJACbk8TDW72F9pnwKqQhM0vzpsbat+kubl5FeO0CPk/Gk2/aAcoP11DNqYAgqvCKEyZlJFmwnC/6JecCBdBb+G/+v894LESD8y4upjZIRdrrC4UQowlm4+6mPJTbB0U+2q7rwv8FXmR9KHmRxtGoMh885bKTXwqOO0pqh0/MMSaW5pzS6s5bUiX7ekl0EPwTyiXbuyUZ3nZcpm/v7lCvXWlyRju8g2pg9e0BShyfI7w1qqw1xEeRVwU1qIlN4Q1bz82t1O+7l308VtiXH2lM9Vhn+Sfz68cjtmJ4uSwZKeV91kaOJdr1OafM9ryfPv2MGDVvSGUk+TEMORysFcRS59VsON8styFJ6hGx1/GKyfUilCS2G2dS/9NvTJjV64nPTQ1mufT4Kd8tBa3/DTmjrqsFjfzYsc/kVz0QsGN7PxgKPf5+aSzrG2y9GQy69jAb6wpMoLcux2zlZvobYR+qjoBIsn+5Y5J0Fs9Jvwh0yd0KGdaDkMZnPGYTQo1vpC4gqowt7q4lba0FRV3jt/bm1B8Pu+YWk4MasNk1wfBMLNOr1CGaiSXFIl0NyATViOOyq6FEnHdF8L1MmLM9v7Yj3l4q5ykF0u/JnDXErC7CwtECRVr6gX3LWfcCAwEAAQ==" } timeout { mining = 20000 block-validation = 1000 } simulator { transaction-feed-interval = 15000 mining-average-interval = 20000 } } |
Note that Artery TCP remoting, as opposed to the classic Netty-base remoting, is used.
With the default configuration, the application will launch an Akka cluster on a single host with two seed nodes at port 2551 and 2552 for additional nodes to join the cluster. Each user can participate the network with their cryptographic public key (for collecting mining reward) provided as an argument for the main program on one of the cluster nodes to perform simulated mining tasks.
For illustration purpose, the main program will either by default enter a periodic mining loop with configurable timeout, or run a ~1 minute quick test by adding “test” to the program’s argument list.
Functional flow of the blockchain application
Rather than stepping through the application logic in text, the following diagram illustrates the functional flow of the Akka actor-based blockchain application:
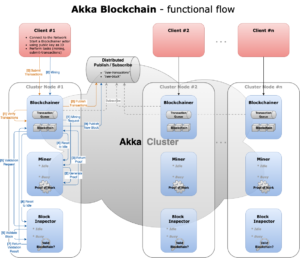
Below is a summary of the key roles played by the various actors in the application:
Blockchainer – A top-level actor that maintains a distributed copy of the blockchain and transaction queue for a given network participant (e.g. a miner) identified by their cryptographic public key. It collects submitted transactions in the queue and updates the blockchain according to the consensual rules via the cluster-wide distributed pub/sub. Playing a managerial role, the actor delegates mining work to actor Miner and validation of mined blocks to actor BlockInspector.
Miner – A child actor of Blockchainer responsible for processing mining tasks, carrying out computationally demanding Proof of Work using a non-blocking routine and returning the proofs back to the parent actor via the Akka ask pattern.
BlockInspector – Another child actor of Blockchainer for validating content of a given block, typically a newly mined block. The validation verifies that generated proof and goes “vertically” down to the nested data structure (transactions/transactionItems, merkleRoot, etc) within a block as well as “horizontally” across all the preceding blocks. The result is then returned to the parent actor via Akka ask.
Simulator – A top-level actor that simulates mining requests and transaction submissions sent to actor Blockchainer. It spawns periodic mining requests by successively calling Akka scheduler function scheduleOnce with randomized variants of configurable time intervals. Transaction submissions are delegated to actor TransactionFeeder.
TransactionFeeder – A child actor of actor Simulator responsible for periodically submitting transactions to actor Blockchainer via an Akka scheduler. Transactions are created with random user accounts and transaction amounts. Since accounts are represented by their cryptographic public keys, a number of PKCS#8 PEM keypair files under “{project-root}/src/main/resources/keys/” were created in advance to save initial setup time.
As for the underlying data structures including Account, Transactions, MerkleTree, Block and ProofOfWork, it’s rather trivial to sort out their inter-relationship by skimming through the relevant classes/companion objects in the source code. For details at the code level of 1) how they constitute the “backbone” of the blockchain, and 2) how Proof of Work is carried out in the mining process, please refer to the previous couple of posts of this mini series.
Complete source code of the blockchain application is available at GitHub.
Test running the blockchain application
Below is sample console output with edited annotations from an Akka cluster of two nodes, each running the blockchain application with the default configuration on its own JVM.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 |
### ### Annotated Console Log: NODE #1 ### sbt:akka-blockchain> runMain akkablockchain.Main 2551 src/main/resources/keys/account0_public.pem runMain akkablockchain.Main 2551 src/main/resources/keys/account0_public.pem [info] Running akkablockchain.Main 2551 src/main/resources/keys/account0_public.pem <<< <<<--- Running on port# 2551 with minerKeyFile `account0_public.pem` <<< [INFO] [04/16/2020 18:08:40.349] [run-main-0] [ArteryTcpTransport(akka://blockchain)] Remoting started with transport [Artery tcp]; listening on address [akka://blockchain@127.0.0.1:2551] with UID [7294460728338242243] [INFO] [04/16/2020 18:08:40.378] [run-main-0] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Starting up, Akka version [2.6.4] ... [INFO] [04/16/2020 18:08:40.466] [run-main-0] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Registered cluster JMX MBean [akka:type=Cluster] [INFO] [04/16/2020 18:08:40.467] [run-main-0] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Started up successfully [INFO] [04/16/2020 18:08:40.570] [blockchain-akka.actor.internal-dispatcher-3] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - No downing-provider-class configured, manual cluster downing required, see https://doc.akka.io/docs/akka/current/typed/cluster.html#downing [INFO] [04/16/2020 18:08:41.056] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Ack] akkablockchain.actor.Blockchainer@e1b6066: Subscribing to 'new-transactions' ... [INFO] [04/16/2020 18:08:41.056] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Ack] akkablockchain.actor.Blockchainer@e1b6066: Subscribing to 'new-block' ... [WARN] [04/16/2020 18:08:41.192] [blockchain-akka.remote.default-remote-dispatcher-8] [akka.stream.Log(akka://blockchain/system/Materializers/StreamSupervisor-1)] [outbound connection to [akka://blockchain@127.0.0.1:2552], message stream] Upstream failed, cause: StreamTcpException: Tcp command [Connect(127.0.0.1:2552,None,List(),Some(5000 milliseconds),true)] failed because of java.net.ConnectException: Connection refused [WARN] [04/16/2020 18:08:41.192] [blockchain-akka.remote.default-remote-dispatcher-9] [akka.stream.Log(akka://blockchain/system/Materializers/StreamSupervisor-1)] [outbound connection to [akka://blockchain@127.0.0.1:2552], control stream] Upstream failed, cause: StreamTcpException: Tcp command [Connect(127.0.0.1:2552,None,List(),Some(5000 milliseconds),true)] failed because of java.net.ConnectException: Connection refused [INFO] [04/16/2020 18:08:42.023] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(1cab, 3000/2, 2020-04-17 01:08:42) is published. [INFO] [04/16/2020 18:08:42.027] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(1cab, 3000/2, 2020-04-17 01:08:42) to transaction queue. [INFO] [akkaMemberChanged][04/16/2020 18:08:45.722] [blockchain-akka.actor.internal-dispatcher-3] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Node [akka://blockchain@127.0.0.1:2551] is JOINING itself (with roles [dc-default]) and forming new cluster [INFO] [04/16/2020 18:08:45.725] [blockchain-akka.actor.internal-dispatcher-3] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - is the new leader among reachable nodes (more leaders may exist) [INFO] [akkaMemberChanged][04/16/2020 18:08:45.732] [blockchain-akka.actor.internal-dispatcher-3] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Leader is moving node [akka://blockchain@127.0.0.1:2551] to [Up] <<< <<<--- Cluster seed node #1, bound to port# 2551, is up <<< [info] new client connected: network-1 [INFO] [04/16/2020 18:08:57.007] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(4700, 4000/2, 2020-04-17 01:08:57) is published. [INFO] [04/16/2020 18:08:57.009] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(4700, 4000/2, 2020-04-17 01:08:57) to transaction queue. [WARN] [04/16/2020 18:09:00.800] [blockchain-akka.remote.default-remote-dispatcher-9] [Association(akka://blockchain)] Outbound control stream to [akka://blockchain@127.0.0.1:2552] failed. Restarting it. akka.remote.artery.OutboundHandshake$HandshakeTimeoutException: Handshake with [akka://blockchain@127.0.0.1:2552] did not complete within 20000 ms [INFO] [04/16/2020 18:09:10.980] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 22000 millis [INFO] [04/16/2020 18:09:10.980] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:09:10.980] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(1cab, 3000/2, 2020-04-17 01:08:42), T(4700, 4000/2, 2020-04-17 01:08:57)) [INFO] [04/16/2020 18:09:10.989] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:09:11.998] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(dea2, 1500/1, 2020-04-17 01:09:11) is published. [INFO] [04/16/2020 18:09:11.999] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(dea2, 1500/1, 2020-04-17 01:09:11) to transaction queue. [INFO] [04/16/2020 18:09:24.812] [blockchain-akka.actor.internal-dispatcher-2] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Received InitJoin message from [Actor[akka://blockchain@127.0.0.1:2552/system/cluster/core/daemon/joinSeedNodeProcess-1#-281590563]] to [akka://blockchain@127.0.0.1:2551] [INFO] [04/16/2020 18:09:24.813] [blockchain-akka.actor.internal-dispatcher-2] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Sending InitJoinAck message from node [akka://blockchain@127.0.0.1:2551] to [Actor[akka://blockchain@127.0.0.1:2552/system/cluster/core/daemon/joinSeedNodeProcess-1#-281590563]] (version [2.6.4]) [INFO] [akkaMemberChanged][04/16/2020 18:09:24.912] [blockchain-akka.actor.internal-dispatcher-6] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Node [akka://blockchain@127.0.0.1:2552] is JOINING, roles [dc-default] [INFO] [akkaMemberChanged][04/16/2020 18:09:25.430] [blockchain-akka.actor.internal-dispatcher-6] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Leader is moving node [akka://blockchain@127.0.0.1:2552] to [Up] <<< <<<--- Allowed node #2, bound to port# 2552, to join the cluster <<< [INFO] [04/16/2020 18:09:26.615] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(20b3, 5000/2, 2020-04-17 01:09:26) to transaction queue. [INFO] [04/16/2020 18:09:27.003] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(1270, 6500/3, 2020-04-17 01:09:27) is published. [INFO] [04/16/2020 18:09:27.004] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(1270, 6500/3, 2020-04-17 01:09:27) to transaction queue. [INFO] [04/16/2020 18:09:32.996] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 17000 millis [INFO] [04/16/2020 18:09:32.996] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:09:33.004] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(4700, 4000/2, 2020-04-17 01:08:57), T(dea2, 1500/1, 2020-04-17 01:09:11), T(20b3, 5000/2, 2020-04-17 01:09:26), T(1270, 6500/3, 2020-04-17 01:09:27)) [INFO] [04/16/2020 18:09:33.005] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:09:38.763] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:09:38.767] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771) is valid. Updating blockchain. <<< <<<--- Adding a locally mined block to local `blockchain` <<< [INFO] [04/16/2020 18:09:38.768] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:09:41.579] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(dd7d, 7000/3, 2020-04-17 01:09:41) to transaction queue. [INFO] [04/16/2020 18:09:42.004] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(af31, 5000/2, 2020-04-17 01:09:42) is published. [INFO] [04/16/2020 18:09:42.004] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(af31, 5000/2, 2020-04-17 01:09:42) to transaction queue. [INFO] [04/16/2020 18:09:50.018] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 20000 millis [INFO] [04/16/2020 18:09:50.018] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:09:50.020] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(dea2, 1500/1, 2020-04-17 01:09:11), T(20b3, 5000/2, 2020-04-17 01:09:26), T(1270, 6500/3, 2020-04-17 01:09:27), T(dd7d, 7000/3, 2020-04-17 01:09:41), T(af31, 5000/2, 2020-04-17 01:09:42)) [INFO] [04/16/2020 18:09:50.020] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:09:56.582] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(c28e, 6500/3, 2020-04-17 01:09:56) to transaction queue. [INFO] [04/16/2020 18:09:56.996] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(6a16, 2000/1, 2020-04-17 01:09:56) is published. [INFO] [04/16/2020 18:09:56.996] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(6a16, 2000/1, 2020-04-17 01:09:56) to transaction queue. [ERROR] [04/16/2020 18:10:08.044] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.Mining] akkablockchain.actor.Blockchainer@e1b6066: ERROR: java.util.concurrent.TimeoutException: BLK(Hg/S, T(4700, 4099/3), 2020-04-17 01:09:50, 3, 0): 18000 milliseconds <<< <<<--- Mining of a block timed out; the assembled block will be discarded <<< [INFO] [04/16/2020 18:10:08.044] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:10:10.036] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 22000 millis [INFO] [04/16/2020 18:10:10.036] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:10:10.036] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(20b3, 5000/2, 2020-04-17 01:09:26), T(1270, 6500/3, 2020-04-17 01:09:27), T(dd7d, 7000/3, 2020-04-17 01:09:41), T(af31, 5000/2, 2020-04-17 01:09:42), T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56)) [INFO] [04/16/2020 18:10:10.036] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:10:11.573] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(a784, 2500/2, 2020-04-17 01:10:11) to transaction queue. [INFO] [04/16/2020 18:10:11.998] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(64bb, 3000/2, 2020-04-17 01:10:11) is published. [INFO] [04/16/2020 18:10:11.998] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(64bb, 3000/2, 2020-04-17 01:10:11) to transaction queue. [INFO] [04/16/2020 18:10:17.526] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662) is valid. Updating blockchain. <<< <<<--- Adding a mined block thru Akka distributed pub/sub to local `blockchain` <<< [INFO] [04/16/2020 18:10:17.526] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:10:26.572] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(1c91, 4500/2, 2020-04-17 01:10:26) to transaction queue. [INFO] [04/16/2020 18:10:26.997] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(ea85, 5000/3, 2020-04-17 01:10:26) is published. [INFO] [04/16/2020 18:10:26.997] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(ea85, 5000/3, 2020-04-17 01:10:26) to transaction queue. [ERROR] [04/16/2020 18:10:28.055] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.Mining] akkablockchain.actor.Blockchainer@e1b6066: ERROR: java.util.concurrent.TimeoutException: BLK(lxoY, T(dea2, 1599/2), 2020-04-17 01:10:10, 3, 0): 18000 milliseconds <<< <<<--- Mining of a block timed out; the assembled block will be discarded <<< [INFO] [04/16/2020 18:10:28.056] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:10:32.053] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 15000 millis [INFO] [04/16/2020 18:10:32.053] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:10:32.054] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(1270, 6500/3, 2020-04-17 01:09:27), T(dd7d, 7000/3, 2020-04-17 01:09:41), T(af31, 5000/2, 2020-04-17 01:09:42), T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26)) [INFO] [04/16/2020 18:10:32.054] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:10:35.550] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.DoneMining received. [ERROR] [04/16/2020 18:10:35.551] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: ERROR: BLK(pryD, T(20b3, 5099/3), 2020-04-17 01:10:32, 3, 4014397) is invalid! <<< <<<--- A mined block failed validation due to associated transactions existing in local `blockchain` <<< [INFO] [04/16/2020 18:10:35.551] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:10:41.571] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(e73e, 4000/2, 2020-04-17 01:10:41) to transaction queue. [INFO] [04/16/2020 18:10:41.995] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(05c4, 2000/2, 2020-04-17 01:10:41) is published. [INFO] [04/16/2020 18:10:41.996] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(05c4, 2000/2, 2020-04-17 01:10:41) to transaction queue. [INFO] [04/16/2020 18:10:42.173] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136) is valid. Updating blockchain. [INFO] [04/16/2020 18:10:42.173] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:10:47.074] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 26000 millis [INFO] [04/16/2020 18:10:47.074] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:10:47.075] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(dd7d, 7000/3, 2020-04-17 01:09:41), T(af31, 5000/2, 2020-04-17 01:09:42), T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41)) [INFO] [04/16/2020 18:10:47.075] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:10:56.570] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(dd31, 2000/1, 2020-04-17 01:10:56) to transaction queue. [INFO] [04/16/2020 18:10:57.000] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(ab28, 3500/2, 2020-04-17 01:10:57) is published. [INFO] [04/16/2020 18:10:57.001] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(ab28, 3500/2, 2020-04-17 01:10:57) to transaction queue. [ERROR] [04/16/2020 18:11:05.093] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.Mining] akkablockchain.actor.Blockchainer@e1b6066: ERROR: java.util.concurrent.TimeoutException: BLK(VGhP, T(1270, 6599/4), 2020-04-17 01:10:47, 3, 0): 18000 milliseconds <<< <<<--- Mining of a block timed out; the assembled block will be discarded <<< [INFO] [04/16/2020 18:11:05.093] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:11:09.680] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597) is valid. Updating blockchain. <<< <<<--- Adding a mined block thru Akka distributed pub/sub to local `blockchain` <<< [INFO] [04/16/2020 18:11:09.680] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:11.573] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(3be4, 4500/3, 2020-04-17 01:11:11) to transaction queue. [INFO] [04/16/2020 18:11:12.003] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(424e, 6000/3, 2020-04-17 01:11:12) is published. [INFO] [04/16/2020 18:11:12.003] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(424e, 6000/3, 2020-04-17 01:11:12) to transaction queue. [INFO] [04/16/2020 18:11:13.093] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 25000 millis [INFO] [04/16/2020 18:11:13.093] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:11:13.094] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(af31, 5000/2, 2020-04-17 01:09:42), T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12)) [INFO] [04/16/2020 18:11:13.094] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:11:18.026] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433) is valid. Updating blockchain. <<< <<<--- Adding a locally mined block to local `blockchain` <<< [INFO] [04/16/2020 18:11:18.026] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:21.022] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.DoneMining received. [ERROR] [04/16/2020 18:11:21.023] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: ERROR: BLK(3FyP, T(dd7d, 7099/4), 2020-04-17 01:11:13, 3, 8943763) is invalid! <<< <<<--- A mined block failed validation due to associated transactions existing in local `blockchain` <<< [INFO] [04/16/2020 18:11:21.023] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:26.563] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(99be, 2500/1, 2020-04-17 01:11:26) to transaction queue. [INFO] [04/16/2020 18:11:27.002] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(0e91, 4000/2, 2020-04-17 01:11:27) is published. [INFO] [04/16/2020 18:11:27.003] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(0e91, 4000/2, 2020-04-17 01:11:27) to transaction queue. [INFO] [04/16/2020 18:11:38.113] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 16000 millis [INFO] [04/16/2020 18:11:38.113] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:11:38.114] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12), T(99be, 2500/1, 2020-04-17 01:11:26), T(0e91, 4000/2, 2020-04-17 01:11:27)) [INFO] [04/16/2020 18:11:38.115] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:11:41.568] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(2e89, 6000/3, 2020-04-17 01:11:41) to transaction queue. [INFO] [04/16/2020 18:11:41.993] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(1925, 1000/1, 2020-04-17 01:11:41) is published. [INFO] [04/16/2020 18:11:41.996] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(1925, 1000/1, 2020-04-17 01:11:41) to transaction queue. [INFO] [04/16/2020 18:11:44.242] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232) is valid. Updating blockchain. <<< <<<--- Adding a mined block thru Akka distributed pub/sub to local `blockchain` <<< [INFO] [04/16/2020 18:11:44.242] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:54.132] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 20000 millis [INFO] [04/16/2020 18:11:54.132] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [ERROR] [04/16/2020 18:11:54.132] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.Mine(BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232), T(c28e, 6500/3, 2020-04-17 01:09:56)) received but akkablockchain.actor.Miner@320de6d4 is busy! [INFO] [04/16/2020 18:11:54.132] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12), T(99be, 2500/1, 2020-04-17 01:11:26), T(0e91, 4000/2, 2020-04-17 01:11:27), T(2e89, 6000/3, 2020-04-17 01:11:41), T(1925, 1000/1, 2020-04-17 01:11:41)) [INFO] [04/16/2020 18:11:54.133] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232), BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [ERROR] [04/16/2020 18:11:54.133] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.Mining] akkablockchain.actor.Blockchainer@e1b6066: ERROR: akkablockchain.actor.Blockchainer$BusyException: akkablockchain.actor.Miner@320de6d4 is busy! <<< <<<--- A mining request rejected by the busy miner; associated transactions to be put back in local `transaction queue` <<< [INFO] [04/16/2020 18:11:54.134] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Prepended T(c28e, 6500/3, 2020-04-17 01:09:56) to transaction queue. [INFO] [04/16/2020 18:11:54.136] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.DoneMining received. [ERROR] [04/16/2020 18:11:54.137] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: ERROR: BLK(yVLA, T(af31, 5099/3), 2020-04-17 01:11:38, 3, 16916400) is invalid! <<< <<<--- A mined block failed validation due to associated transactions existing in local `blockchain` <<< [INFO] [04/16/2020 18:11:54.137] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:56.565] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(7d6c, 7500/3, 2020-04-17 01:11:56) to transaction queue. [INFO] [04/16/2020 18:11:57.000] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(3002, 8000/3, 2020-04-17 01:11:57) is published. [INFO] [04/16/2020 18:11:57.001] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(3002, 8000/3, 2020-04-17 01:11:57) to transaction queue. [INFO] [04/16/2020 18:11:57.305] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: BLK(l++u, T(6a16, 2099/2), 2020-04-17 01:11:46, 3, 11875208) is valid. Updating blockchain. <<< <<<--- Adding a locally mined block to local `blockchain` <<< [INFO] [04/16/2020 18:11:57.305] [blockchain-akka.actor.default-dispatcher-12] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:12:11.570] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(bd60, 1000/1, 2020-04-17 01:12:11) to transaction queue. [INFO] [04/16/2020 18:12:11.993] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(26a0, 3000/1, 2020-04-17 01:12:11) is published. [INFO] [04/16/2020 18:12:11.994] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(26a0, 3000/1, 2020-04-17 01:12:11) to transaction queue. [INFO] [04/16/2020 18:12:14.150] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 16000 millis [INFO] [04/16/2020 18:12:14.150] [blockchain-akka.actor.default-dispatcher-29] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:12:14.151] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12), T(99be, 2500/1, 2020-04-17 01:11:26), T(0e91, 4000/2, 2020-04-17 01:11:27), T(2e89, 6000/3, 2020-04-17 01:11:41), T(1925, 1000/1, 2020-04-17 01:11:41), T(7d6c, 7500/3, 2020-04-17 01:11:56), T(3002, 8000/3, 2020-04-17 01:11:57), T(bd60, 1000/1, 2020-04-17 01:12:11), T(26a0, 3000/1, 2020-04-17 01:12:11)) [INFO] [04/16/2020 18:12:14.151] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(l++u, T(6a16, 2099/2), 2020-04-17 01:11:46, 3, 11875208), BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232), BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:12:14.791] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@e1b6066: BLK(g+dc, T(a784, 2599/3), 2020-04-17 01:12:10, 3, 4362943) is valid. Updating blockchain. <<< <<<--- Adding a mined block thru Akka distributed pub/sub to local `blockchain` <<< [INFO] [04/16/2020 18:12:14.791] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [WARN] [akkaUnreachable][04/16/2020 18:12:23.924] [blockchain-akka.actor.internal-dispatcher-11] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Marking node as UNREACHABLE [Member(address = akka://blockchain@127.0.0.1:2552, status = Up)]. [INFO] [04/16/2020 18:12:27.000] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(4632, 4000/3, 2020-04-17 01:12:27) is published. [INFO] [04/16/2020 18:12:27.001] [blockchain-akka.actor.default-dispatcher-30] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(4632, 4000/3, 2020-04-17 01:12:27) to transaction queue. [INFO] [akkaDeadLetter][04/16/2020 18:12:27.102] [blockchain-akka.actor.default-dispatcher-30] [akka://blockchain/deadLetters] Message [akka.cluster.GossipStatus] from Actor[akka://blockchain/system/cluster/core/daemon#1177403680] to Actor[akka://blockchain/deadLetters] was not delivered. [1] dead letters encountered. If this is not an expected behavior then Actor[akka://blockchain/deadLetters] may have terminated unexpectedly. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [INFO] [akkaDeadLetter][04/16/2020 18:12:27.102] [blockchain-akka.actor.default-dispatcher-30] [akka://blockchain/deadLetters] Message [akka.cluster.GossipStatus] from Actor[akka://blockchain/system/cluster/core/daemon#1177403680] to Actor[akka://blockchain/deadLetters] was not delivered. [2] dead letters encountered. If this is not an expected behavior then Actor[akka://blockchain/deadLetters] may have terminated unexpectedly. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [INFO] [akkaDeadLetter][04/16/2020 18:12:27.102] [blockchain-akka.actor.default-dispatcher-30] [akka://blockchain@127.0.0.1:2552/system/distributedPubSubMediator/new-transactions] Message [akkablockchain.actor.Blockchainer$AddTransactions] from Actor[akka://blockchain/user/blockchainer#559536709] to Actor[akka://blockchain@127.0.0.1:2552/system/distributedPubSubMediator/new-transactions#1378150251] was not delivered. [3] dead letters encountered. If this is not an expected behavior then Actor[akka://blockchain@127.0.0.1:2552/system/distributedPubSubMediator/new-transactions#1378150251] may have terminated unexpectedly. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [WARN] [04/16/2020 18:12:27.451] [blockchain-akka.remote.default-remote-dispatcher-5] [akka.stream.Log(akka://blockchain/system/Materializers/StreamSupervisor-1)] [outbound connection to [akka://blockchain@127.0.0.1:2552], message stream] Upstream failed, cause: StreamTcpException: Tcp command [Connect(127.0.0.1:2552,None,List(),Some(5000 milliseconds),true)] failed because of java.net.ConnectException: Connection refused <<< <<<--- Detected cluster node #2 no longer reachable <<< [INFO] [04/16/2020 18:12:30.171] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Start mining in 21000 millis [INFO] [04/16/2020 18:12:30.172] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [ERROR] [04/16/2020 18:12:30.172] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.Mine(BLK(g+dc, T(a784, 2599/3), 2020-04-17 01:12:10, 3, 4362943), T(6a16, 2000/1, 2020-04-17 01:09:56)) received but akkablockchain.actor.Miner@320de6d4 is busy! <<< <<<--- A mining request rejected by the busy miner; associated transactions to be put back in local `transaction queue` <<< [ERROR] [04/16/2020 18:12:30.172] [blockchain-akka.actor.default-dispatcher-30] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.Mining] akkablockchain.actor.Blockchainer@e1b6066: ERROR: akkablockchain.actor.Blockchainer$BusyException: akkablockchain.actor.Miner@320de6d4 is busy! [INFO] [04/16/2020 18:12:30.172] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Transaction queue: Queue(T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12), T(99be, 2500/1, 2020-04-17 01:11:26), T(0e91, 4000/2, 2020-04-17 01:11:27), T(2e89, 6000/3, 2020-04-17 01:11:41), T(1925, 1000/1, 2020-04-17 01:11:41), T(7d6c, 7500/3, 2020-04-17 01:11:56), T(3002, 8000/3, 2020-04-17 01:11:57), T(bd60, 1000/1, 2020-04-17 01:12:11), T(26a0, 3000/1, 2020-04-17 01:12:11), T(4632, 4000/3, 2020-04-17 01:12:27)) [INFO] [04/16/2020 18:12:30.172] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Prepended T(6a16, 2000/1, 2020-04-17 01:09:56) to transaction queue. [INFO] [04/16/2020 18:12:30.173] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/simulator] [MiningLoop] Blockchain: List(BLK(g+dc, T(a784, 2599/3), 2020-04-17 01:12:10, 3, 4362943), BLK(l++u, T(6a16, 2099/2), 2020-04-17 01:11:46, 3, 11875208), BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232), BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [ERROR] [04/16/2020 18:12:32.172] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.Mining] akkablockchain.actor.Blockchainer@e1b6066: ERROR: java.util.concurrent.TimeoutException: BLK(d13g, T(c28e, 6599/4), 2020-04-17 01:12:14, 3, 0): 18000 milliseconds [INFO] [04/16/2020 18:12:32.172] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer/miner] [Mining] Miner.DoneMining received. [WARN] [04/16/2020 18:12:35.612] [blockchain-akka.remote.default-remote-dispatcher-9] [akka.stream.Log(akka://blockchain/system/Materializers/StreamSupervisor-1)] [outbound connection to [akka://blockchain@127.0.0.1:2552], message stream] Upstream failed, cause: StreamTcpException: Tcp command [Connect(127.0.0.1:2552,None,List(),Some(5000 milliseconds),true)] failed because of java.net.ConnectException: Connection refused [INFO] [04/16/2020 18:12:41.997] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@e1b6066: T(552a, 4000/2, 2020-04-17 01:12:41) is published. [INFO] [04/16/2020 18:12:41.997] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2551/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@e1b6066: Appended T(552a, 4000/2, 2020-04-17 01:12:41) to transaction queue. [INFO] [akkaDeadLetter][04/16/2020 18:12:43.022] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2552/system/distributedPubSubMediator/new-transactions] Message [akkablockchain.actor.Blockchainer$AddTransactions] from Actor[akka://blockchain/user/blockchainer#559536709] to Actor[akka://blockchain@127.0.0.1:2552/system/distributedPubSubMediator/new-transactions#1378150251] was not delivered. [4] dead letters encountered. If this is not an expected behavior then Actor[akka://blockchain@127.0.0.1:2552/system/distributedPubSubMediator/new-transactions#1378150251] may have terminated unexpectedly. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'. [WARN] [04/16/2020 18:12:43.767] [blockchain-akka.remote.default-remote-dispatcher-9] [akka.stream.Log(akka://blockchain/system/Materializers/StreamSupervisor-1)] [outbound connection to [akka://blockchain@127.0.0.1:2552], message stream] Upstream failed, cause: StreamTcpException: Tcp command [Connect(127.0.0.1:2552,None,List(),Some(5000 milliseconds),true)] failed because of java.net.ConnectException: Connection refused [INFO] [akkaClusterLeaderIncapacitated][04/16/2020 18:12:44.327] [blockchain-akka.actor.internal-dispatcher-3] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2551] - Leader can currently not perform its duties, reachability status: [akka://blockchain@127.0.0.1:2551 -> akka://blockchain@127.0.0.1:2552: Unreachable [Unreachable] (1)], member status: [akka://blockchain@127.0.0.1:2551 Up seen=true, akka://blockchain@127.0.0.1:2552 Up seen=false] Process finished with exit code 137 (interrupted by signal 9: SIGKILL) <<< <<<--- User terminated program on the node <<< |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
### ### Annotated Console Log: NODE #2 ### sbt:akka-blockchain> runMain akkablockchain.Main 2552 src/main/resources/keys/account1_public.pem runMain akkablockchain.Main 2552 src/main/resources/keys/account1_public.pem <<< <<<--- Running on port# 2552, also a seed node, with minerKeyFile `account1_public.pem` <<< [info] Running akkablockchain.Main 2552 src/main/resources/keys/account1_public.pem [INFO] [04/16/2020 18:09:24.088] [run-main-0] [ArteryTcpTransport(akka://blockchain)] Remoting started with transport [Artery tcp]; listening on address [akka://blockchain@127.0.0.1:2552] with UID [7768051775546777328] [INFO] [04/16/2020 18:09:24.112] [run-main-0] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2552] - Starting up, Akka version [2.6.4] ... [INFO] [04/16/2020 18:09:24.217] [run-main-0] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2552] - Registered cluster JMX MBean [akka:type=Cluster] [INFO] [04/16/2020 18:09:24.217] [run-main-0] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2552] - Started up successfully [INFO] [04/16/2020 18:09:24.271] [blockchain-akka.actor.internal-dispatcher-6] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2552] - No downing-provider-class configured, manual cluster downing required, see https://doc.akka.io/docs/akka/current/typed/cluster.html#downing [INFO] [04/16/2020 18:09:24.594] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Ack] akkablockchain.actor.Blockchainer@608e81c9: Subscribing to 'new-transactions' ... [INFO] [04/16/2020 18:09:24.594] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Ack] akkablockchain.actor.Blockchainer@608e81c9: Subscribing to 'new-block' ... [INFO] [04/16/2020 18:09:24.884] [blockchain-akka.actor.internal-dispatcher-3] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2552] - Received InitJoinAck message from [Actor[akka://blockchain@127.0.0.1:2551/system/cluster/core/daemon#1177403680]] to [akka://blockchain@127.0.0.1:2552] [INFO] [04/16/2020 18:09:24.975] [blockchain-akka.actor.internal-dispatcher-2] [Cluster(akka://blockchain)] Cluster Node [akka://blockchain@127.0.0.1:2552] - Welcome from [akka://blockchain@127.0.0.1:2551] <<< <<<--- Seed node #2, bound to port# 2552, joined the cluster <<< [INFO] [04/16/2020 18:09:26.591] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(20b3, 5000/2, 2020-04-17 01:09:26) is published. [INFO] [04/16/2020 18:09:26.594] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(20b3, 5000/2, 2020-04-17 01:09:26) to transaction queue. [INFO] [04/16/2020 18:09:27.015] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(1270, 6500/3, 2020-04-17 01:09:27) to transaction queue. [INFO] [04/16/2020 18:09:38.795] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771) is valid. Updating blockchain. <<< <<<--- Adding a mined block thru Akka distributed pub/sub to local `blockchain` <<< [INFO] [04/16/2020 18:09:38.796] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:09:41.575] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(dd7d, 7000/3, 2020-04-17 01:09:41) is published. [INFO] [04/16/2020 18:09:41.576] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(dd7d, 7000/3, 2020-04-17 01:09:41) to transaction queue. [INFO] [04/16/2020 18:09:42.008] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(af31, 5000/2, 2020-04-17 01:09:42) to transaction queue. [INFO] [04/16/2020 18:09:54.548] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Start mining in 16000 millis [INFO] [04/16/2020 18:09:54.548] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:09:54.549] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Transaction queue: Queue(T(20b3, 5000/2, 2020-04-17 01:09:26), T(1270, 6500/3, 2020-04-17 01:09:27), T(dd7d, 7000/3, 2020-04-17 01:09:41), T(af31, 5000/2, 2020-04-17 01:09:42)) [INFO] [04/16/2020 18:09:54.549] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Blockchain: List(BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:09:56.576] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(c28e, 6500/3, 2020-04-17 01:09:56) is published. [INFO] [04/16/2020 18:09:56.578] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(c28e, 6500/3, 2020-04-17 01:09:56) to transaction queue. [INFO] [04/16/2020 18:09:56.998] [blockchain-akka.actor.default-dispatcher-14] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(6a16, 2000/1, 2020-04-17 01:09:56) to transaction queue. [INFO] [04/16/2020 18:10:10.563] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Start mining in 25000 millis [INFO] [04/16/2020 18:10:10.563] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:10:10.565] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Transaction queue: Queue(T(1270, 6500/3, 2020-04-17 01:09:27), T(dd7d, 7000/3, 2020-04-17 01:09:41), T(af31, 5000/2, 2020-04-17 01:09:42), T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56)) [INFO] [04/16/2020 18:10:10.565] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Blockchain: List(BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:10:11.570] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(a784, 2500/2, 2020-04-17 01:10:11) is published. [INFO] [04/16/2020 18:10:11.570] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(a784, 2500/2, 2020-04-17 01:10:11) to transaction queue. [INFO] [04/16/2020 18:10:12.001] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(64bb, 3000/2, 2020-04-17 01:10:11) to transaction queue. [INFO] [04/16/2020 18:10:17.518] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:10:17.520] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662) is valid. Updating blockchain. <<< <<<--- Adding a locally mined block to local `blockchain` <<< [INFO] [04/16/2020 18:10:17.521] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:10:26.569] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(1c91, 4500/2, 2020-04-17 01:10:26) is published. [INFO] [04/16/2020 18:10:26.569] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(1c91, 4500/2, 2020-04-17 01:10:26) to transaction queue. [INFO] [04/16/2020 18:10:26.999] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(ea85, 5000/3, 2020-04-17 01:10:26) to transaction queue. [ERROR] [04/16/2020 18:10:35.565] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: ERROR: BLK(pryD, T(20b3, 5099/3), 2020-04-17 01:10:32, 3, 4014397) is invalid! <<< <<<--- A mined block failed validation due to associated transactions existing in local `blockchain` <<< [INFO] [04/16/2020 18:10:35.566] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:10:35.581] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Start mining in 23000 millis [INFO] [04/16/2020 18:10:35.581] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:10:35.582] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Transaction queue: Queue(T(dd7d, 7000/3, 2020-04-17 01:09:41), T(af31, 5000/2, 2020-04-17 01:09:42), T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26)) [INFO] [04/16/2020 18:10:35.582] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Blockchain: List(BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:10:41.568] [blockchain-akka.actor.default-dispatcher-25] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(e73e, 4000/2, 2020-04-17 01:10:41) is published. [INFO] [04/16/2020 18:10:41.569] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(e73e, 4000/2, 2020-04-17 01:10:41) to transaction queue. [INFO] [04/16/2020 18:10:41.997] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(05c4, 2000/2, 2020-04-17 01:10:41) to transaction queue. [INFO] [04/16/2020 18:10:42.165] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:10:42.167] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136) is valid. Updating blockchain. <<< <<<--- Adding a mined block thru Akka distributed pub/sub to local `blockchain` <<< [INFO] [04/16/2020 18:10:42.167] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:10:56.567] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(dd31, 2000/1, 2020-04-17 01:10:56) is published. [INFO] [04/16/2020 18:10:56.568] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(dd31, 2000/1, 2020-04-17 01:10:56) to transaction queue. [INFO] [04/16/2020 18:10:57.003] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(ab28, 3500/2, 2020-04-17 01:10:57) to transaction queue. [INFO] [04/16/2020 18:10:58.601] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Start mining in 16000 millis [INFO] [04/16/2020 18:10:58.601] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:10:58.603] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Transaction queue: Queue(T(af31, 5000/2, 2020-04-17 01:09:42), T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57)) [INFO] [04/16/2020 18:10:58.604] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Blockchain: List(BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:11:09.668] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:11:09.672] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597) is valid. Updating blockchain. <<< <<<--- Adding a locally mined block to local `blockchain` <<< [INFO] [04/16/2020 18:11:09.672] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:11.570] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(3be4, 4500/3, 2020-04-17 01:11:11) is published. [INFO] [04/16/2020 18:11:11.571] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(3be4, 4500/3, 2020-04-17 01:11:11) to transaction queue. [INFO] [04/16/2020 18:11:12.005] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(424e, 6000/3, 2020-04-17 01:11:12) to transaction queue. [INFO] [04/16/2020 18:11:14.619] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Start mining in 17000 millis [INFO] [04/16/2020 18:11:14.619] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:11:14.620] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Transaction queue: Queue(T(c28e, 6500/3, 2020-04-17 01:09:56), T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12)) [INFO] [04/16/2020 18:11:14.621] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Blockchain: List(BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:11:18.014] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:11:18.019] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433) is valid. Updating blockchain. <<< <<<--- Adding a mined block thru Akka distributed pub/sub to local `blockchain` <<< [INFO] [04/16/2020 18:11:18.019] [blockchain-akka.actor.default-dispatcher-4] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [ERROR] [04/16/2020 18:11:21.031] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: ERROR: BLK(3FyP, T(dd7d, 7099/4), 2020-04-17 01:11:13, 3, 8943763) is invalid! <<< <<<--- A mined block failed validation due to associated transactions existing in local `blockchain` <<< [INFO] [04/16/2020 18:11:21.031] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:26.561] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(99be, 2500/1, 2020-04-17 01:11:26) is published. [INFO] [04/16/2020 18:11:26.562] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(99be, 2500/1, 2020-04-17 01:11:26) to transaction queue. [INFO] [04/16/2020 18:11:27.005] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(0e91, 4000/2, 2020-04-17 01:11:27) to transaction queue. [INFO] [04/16/2020 18:11:31.639] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Start mining in 15000 millis [INFO] [04/16/2020 18:11:31.639] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:11:31.640] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Transaction queue: Queue(T(6a16, 2000/1, 2020-04-17 01:09:56), T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12), T(99be, 2500/1, 2020-04-17 01:11:26), T(0e91, 4000/2, 2020-04-17 01:11:27)) [INFO] [04/16/2020 18:11:31.640] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Blockchain: List(BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:11:41.565] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(2e89, 6000/3, 2020-04-17 01:11:41) is published. [INFO] [04/16/2020 18:11:41.566] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(2e89, 6000/3, 2020-04-17 01:11:41) to transaction queue. [INFO] [04/16/2020 18:11:41.998] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(1925, 1000/1, 2020-04-17 01:11:41) to transaction queue. [INFO] [04/16/2020 18:11:44.227] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:11:44.231] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232) is valid. Updating blockchain. <<< <<<--- Adding a locally mined block to local `blockchain` <<< [INFO] [04/16/2020 18:11:44.231] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:46.659] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Start mining in 24000 millis [INFO] [04/16/2020 18:11:46.659] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:11:46.660] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Transaction queue: Queue(T(a784, 2500/2, 2020-04-17 01:10:11), T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12), T(99be, 2500/1, 2020-04-17 01:11:26), T(0e91, 4000/2, 2020-04-17 01:11:27), T(2e89, 6000/3, 2020-04-17 01:11:41), T(1925, 1000/1, 2020-04-17 01:11:41)) [INFO] [04/16/2020 18:11:46.660] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Blockchain: List(BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232), BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [ERROR] [04/16/2020 18:11:54.143] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: ERROR: BLK(yVLA, T(af31, 5099/3), 2020-04-17 01:11:38, 3, 16916400) is invalid! <<< <<<--- A mined block failed validation due to associated transactions existing in local `blockchain` <<< [INFO] [04/16/2020 18:11:54.143] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:11:56.562] [blockchain-akka.actor.default-dispatcher-13] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(7d6c, 7500/3, 2020-04-17 01:11:56) is published. [INFO] [04/16/2020 18:11:56.563] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(7d6c, 7500/3, 2020-04-17 01:11:56) to transaction queue. [INFO] [04/16/2020 18:11:57.003] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(3002, 8000/3, 2020-04-17 01:11:57) to transaction queue. [INFO] [04/16/2020 18:11:57.295] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:11:57.301] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: BLK(l++u, T(6a16, 2099/2), 2020-04-17 01:11:46, 3, 11875208) is valid. Updating blockchain. <<< <<<--- Adding a mined block thru Akka distributed pub/sub to local `blockchain` <<< [INFO] [04/16/2020 18:11:57.301] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. [INFO] [04/16/2020 18:12:10.678] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Start mining in 16000 millis [INFO] [04/16/2020 18:12:10.678] [blockchain-akka.actor.default-dispatcher-27] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Getting transaction queue and blockchain ... [INFO] [04/16/2020 18:12:10.679] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Transaction queue: Queue(T(64bb, 3000/2, 2020-04-17 01:10:11), T(1c91, 4500/2, 2020-04-17 01:10:26), T(ea85, 5000/3, 2020-04-17 01:10:26), T(e73e, 4000/2, 2020-04-17 01:10:41), T(05c4, 2000/2, 2020-04-17 01:10:41), T(dd31, 2000/1, 2020-04-17 01:10:56), T(ab28, 3500/2, 2020-04-17 01:10:57), T(3be4, 4500/3, 2020-04-17 01:11:11), T(424e, 6000/3, 2020-04-17 01:11:12), T(99be, 2500/1, 2020-04-17 01:11:26), T(0e91, 4000/2, 2020-04-17 01:11:27), T(2e89, 6000/3, 2020-04-17 01:11:41), T(1925, 1000/1, 2020-04-17 01:11:41), T(7d6c, 7500/3, 2020-04-17 01:11:56), T(3002, 8000/3, 2020-04-17 01:11:57)) [INFO] [04/16/2020 18:12:10.680] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/simulator] [MiningLoop] Blockchain: List(BLK(l++u, T(6a16, 2099/2), 2020-04-17 01:11:46, 3, 11875208), BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232), BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0)) [INFO] [04/16/2020 18:12:11.567] [blockchain-akka.actor.default-dispatcher-28] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Req.SubmitTransactions] akkablockchain.actor.Blockchainer@608e81c9: T(bd60, 1000/1, 2020-04-17 01:12:11) is published. [INFO] [04/16/2020 18:12:11.568] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(bd60, 1000/1, 2020-04-17 01:12:11) to transaction queue. [INFO] [04/16/2020 18:12:11.996] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.AddTransactions] akkablockchain.actor.Blockchainer@608e81c9: Appended T(26a0, 3000/1, 2020-04-17 01:12:11) to transaction queue. [INFO] [04/16/2020 18:12:14.774] [blockchain-akka.actor.default-dispatcher-15] [akka://blockchain@127.0.0.1:2552/user/blockchainer/miner] [Mining] Miner.DoneMining received. [INFO] [04/16/2020 18:12:14.786] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer] [Cmd.UpdateBlockchain] akkablockchain.actor.Blockchainer@608e81c9: BLK(g+dc, T(a784, 2599/3), 2020-04-17 01:12:10, 3, 4362943) is valid. Updating blockchain. <<< <<<--- Adding a locally mined block to local `blockchain` <<< [INFO] [04/16/2020 18:12:14.786] [blockchain-akka.actor.default-dispatcher-26] [akka://blockchain@127.0.0.1:2552/user/blockchainer/blockInspector] [Validation] BlockInspector.DoneValidation received. Process finished with exit code 137 (interrupted by signal 9: SIGKILL) <<< <<<--- User terminated program on the node <<< |
Note that, for illustration purpose, each block as defined in trait Block‘s toString method:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
sealed trait Block { def hash: Array[Byte] def hashPrev: Array[Byte] def merkleRoot: MerkleTree def transactions: Transactions def timestamp: Long def difficulty: Int def nonce: Long def length: Int override def toString: String = { val datetime = timestampToDateTime(timestamp) val transInfo = s"T(${transactions.id.substring(0, 4)}, ${transactions.items.map(_.amount).sum}/${transactions.items.size})" s"BLK(${bytesToBase64(hash).substring(0, 4)}, ${transInfo}, ${datetime}, ${difficulty}, ${nonce})" } } |
is represented in an abbreviated format as:
|
1 |
BLK( hash, Trans(id, total-amount/num-of-trans), date-time, difficulty, proof ) |
where proof is the first incremented nonce value in PoW that satisfies the requirement at the specified difficulty level.
As can be seen in the latest copies of blockchain maintained on the individual cluster nodes, they get updated via distributed pub/sub in accordance with the consensual rule, but still may differ from each other (typically by one or more most recently added blocks) when examined at any given point of time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
// Blockchain on Node #1 [04/16/2020 18:12:30 US/Pacific]: List( BLK(g+dc, T(a784, 2599/3), 2020-04-17 01:12:10, 3, 4362943), BLK(l++u, T(6a16, 2099/2), 2020-04-17 01:11:46, 3, 11875208), BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232), BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0) ) // Blockchain on Node #2 [04/16/2020 18:12:10 US/Pacific]: List( BLK(l++u, T(6a16, 2099/2), 2020-04-17 01:11:46, 3, 11875208), BLK(yIsc, T(c28e, 6599/4), 2020-04-17 01:11:31, 3, 13515232), BLK(9+Ca, T(af31, 5099/3), 2020-04-17 01:11:14, 3, 3918433), BLK(vuLL, T(dd7d, 7099/4), 2020-04-17 01:10:58, 3, 11900597), BLK(zycW, T(1270, 6599/4), 2020-04-17 01:10:35, 3, 8360136), BLK(639L, T(20b3, 5099/3), 2020-04-17 01:10:10, 3, 7614662), BLK(n6T2, T(1cab, 3099/3), 2020-04-17 01:09:33, 3, 7028771), BLK(XF1C, T(----, 0/0), 1970-01-01 00:00:00, 0, 0) ) |
Reliability and efficiency
The application is primarily for proof of concept, hence the abundant side-effecting console logging for illustration purpose. From a reliability and efficiency perspective, it would benefit from the following enhancements to be slightly more robust:
- Fault tolerance: Akka Persistence via journals and snapshots over Redis, Cassandra, etc, woud help recover an actor’s state in case of a system crash. In particular, the distributed
blockchaincopy (and maybetransactionQueueas well) maintained within actor Blockchainer could be crash-proofed with persistence. One approach would be to refactor actor Blockchainer to delegate maintenance ofblockchainto a dedicated child PersistentActor. - Serialization: Akka’s default Java serializer is known for not being very efficient. Other serializers such as Protocol Buffers, Kryo should be considered.
Feature enhancement
Feature-wise, the following enhancements would help make the application one step closer to a real-world cryptocurrency system:
- Data privacy: Currently the transactions stored in the blockchain isn’t encrypted, despite PKCS public keys are being used within individual transactions. The individual transaction items could be encrypted, each of which to be stored with the associated cryptographic public key/signature, requiring miners to validate the signature while allowing only those who have the private key for certain transactions to see the content.
- Self regulation: A self-regulatory mechanism that adjusts the difficulty level of the Proof of Work in accordance with network load would help stabilize the currency. As an example, in a recent drastic plunge of the Bitcoin market value in mid March, there was reportedly a significant self-regulatory reduction in the PoW difficulty to temporarily make mining more rewarding that helped dampen the fall.
- Currency supply: In a cryptocurrency like Bitcoin, issuance of the mining reward by the network is essentially the “minting” of the digital coins. To keep inflation rate under control as the currency supply grows, the rate of coin minting must be proportionately regulated over time. For instance, Bitcoin has a periodic “halfing” mechanism that reduces the mining reward by half for every 210,000 blocks added to the blockchain and will cease producing new coins once the total supply reaches 21 million coins.
- Blockchain versioning: Versioning of the blockchain would make it possible for future algorithmic changes by means of a
fork, akin to Bitcoin’s soft/hard forks, without having to discard the old system. - User Interface: The existing application focuses mainly on how to operate a blockchain network, thus supplementing it with, say, a Web-based user interface (e.g. using Play framework) would certainly make it a more complete system.