
At a startup company, DwellAware, I’ve been with recently, I was tasked to build a web-centric application with a backend for comprehensive data analytics in the residential real estate space. Nevertheless, this post is not about the startup venture. It’s about Node.js, the technology stack chosen to power the application. Programming platforms considered at the beginning of the venture include Scala/Play, PHP/Laravel, Python/Twisted, Ruby/Sinatra and Javascript/Node.js.
Neither is it a blog post about comparing programming platforms. I’m going to simply state that Node.js was picked mainly for a few reasons:
- its lean-and-mean minimalist design principle is in line with how I would like to run things in general,
- its event-driven, non-blocking-I/O architecture is well suited for contemporary high-concurrency web-centric applications, and,
- keeping the entire web application to a single programming platform, since contemporary client-side features are heavily and ubiquitously implemented using Javascript anyway.
Is adopting Node.js a justifiable risk?
In fact, that was the original title of the blog post. I was going to blog about the necessary research for adopting Node.js as the tech stack for the core web application back in 2013. It never grew to more than a few bullet points and was soon buried deep down the priority to-do list.
Javascript has been used on the client side in web applications for a long time. Handling non-blocking events triggered by human activities on a web browser is one thing, dealing with split-second server events and I/O activities on the server side in a non-blocking fashion is a little different. Node.js’s underlying event-driven non-blocking architecture does help somewhat flatten the learning curve to Javascript developers.
Although new Node modules emerged almost daily to try address just about anything in any problem space one could think of, not many of them prove to be very useful, let alone production-grade. That was two years ago. Admittedly, a lot has changed over the past couple of years and Node has definitely become more mature everyday. By most standards, Node.js is still a relatively young technology though.
Anyway, let’s rewind back to Fall 2013.
Built on Google’s V8 Javascript engine, Node is a Javascript-based server platform designed to efficiently run I/O-intensive server applications. For a long time, Javascript was being considered a client-side-only technology. Node.js has made it a serious contender for server-side technology. The fact that prominent software companies such as Microsoft, eBay, LinkedIn, adopted Node.js in some of their products/services was more or less testimonial. While hypes about certain seemingly arbitrary technologies have always been a phenomenon in the Silicon Valley, I wouldn’t characterize the recent uprising of Javascript and Node a mere hype.
Node.js modules
Node by itself is just a barebone server, hence picking suitable modules was one of the upfront tasks. One of the core modules that was an essential part of Node’s middleware framework is Connect, which provides chaining of functions and enhances Node’s http module. ExpressJS further equips Node with rich web app features on top of Connect. To take advantage of multi-core/processor server configuration, Node offers a method child_process.fork() for spawning worker processes that are capable of communicating with their parent via built-in IPC (Inter-process Communication).
On build tool, we started out with Grunt then later shifted to Gulp partly for the speed due to Gulp’s streaming approach. But we were happy with Grunt as well. Node uses Jade as its default templating engine. We didn’t like the performance, so we evaluated a couple of alternate templating engines including doT.js and Swig, and were shocked to see performance gain in an order of magnitude. We promptly switched to Swig (with doT.js a close second).
On test framework, we used Mocha.js with assertion libray, Chai.js, which supports BDD (Behavior-driven Development) assertion style.
Data persistence, caching, content delivery, etc
A key part of our product offerings is about data intelligence, thus databases for both OLTP and warehousing are critical components of the technology stack. MongoDB has been a default database choice for many Node.js applications for good reasons. The emerging MEAN (MongoDB-ExpressJS-AngularJS-Node.js) framework hints the popularity of the Node-MongoDB combo. So Mongo was definitely a considered database. After careful consideration, we decided to go with MySQL. One consideration being that it wouldn’t be too hard to hire a DBA/devops with MySQL experience given its popularity. Both Node.js and MongoDB were relatively new products and we didn’t have in-house MongoDB expertise at the time, so taming one beast (Node in this case) at a time was a preferred route.
There weren’t many Node-MySQL modules out there, though we managed to adopt a simplistic MySQL module that also provides simple connection pooling. Later on, due to the superior geospatial functionality of PostGIS available in the PostgreSQL ecosystem, we migrated from MySQL to PostgreSQL. Thanks to the vast Node.js module repository, there were Node-PostgreSQL modules readily available for connection pooling. To cache frequently referenced application data, we used Redis as a centralized cache store.
Besides dynamic content rendered by application, we were building a web presence also with a lot of static content of various types including images and certain client-side application data. To serve static web content, a few typical approaches, including using a proxy web server, content delivery network (CDN), have been reviewed. On proxy server, Nginx has been on its rise to overtake Apache to become the most popular HTTP server. Its minimalist design is kind of like Node’s. We did some load-testing of static content on Node which appears to be a rather efficient static content server. We decided a proxy server wasn’t necessary at least in the immediate term. As to CDN, we used Amazon’s CloudFront.
Score calculation & image processing
Part of the core value proposition of the product was to come up with objective scores in individual residential real estate properties and neighborhoods so as to help users to make intelligent choice in buying/selling their homes. As described in a previous blog post, a lot of data science work in a wide spectrum of areas (cost analysis, crime, schools, comfort, noise, etc) was performed to generate the scores.
Based on the computed scores, we then derived badges for qualified real estate properties in different areas (e.g. “Low Energy Bills”, “Safe Neighborhood”, “Top Rated Elementary School”). The badges were embedded in selected photos of individual real estate properties, which could then be fed back into the listings distribution cycle by resubmitting into the associated MLSes if the real estate agents/brokers chose to.
All the necessary score calculation and image processing for badges were done in the backend on a Python platform with PostgreSQL databases. Python Tornado servers were used as data service API along with basic caching for Node.js to consume data as presentation content.
Here’s a screen-shot of the Dwelling Page for a given real estate property, showing its DwellScore:
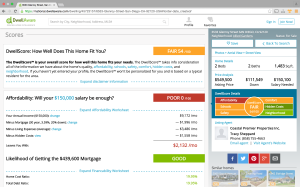
Geospatial maps & search
For geographical maps and search, Google Maps API was extensively used from within Node.js. We gecoded in advance all real estate property addresses using the API as part of the backend data processing routine so as to take advantage of Google’s superior search capability.
To supplement the already pretty robust Google Maps search from within Node.js to better utilize our own geospatial data content, we experimented using an Elasticsearch module which comes with their n-gram lexical analyzer for fuzzy-match search. The test result was promising. An advantage of using such an autonomous search system is that it doesn’t directly tax on the Node.js server or the PostgreSQL database (e.g. pg_trgm) as traffic load increases.
Below is a screen-shot of the Search Page centering around San Diego:
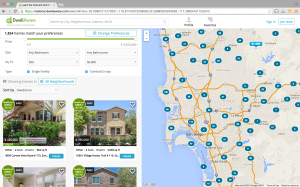
Fast-forward to the present
As mentioned earlier, Node.js has evolved quite a bit over the past couple of years — the rather significant feature/performance improvements from the v0.10 to v0.12, the next LTS (long-term-support) release incorporating the latest V8 Javascript engine and ES6 ECMA features, the fork-off to io.js which later merged back to Node, …, all sound promising and exciting.
In conclusion, given the evident progress of Node’s development I’d say it’s now hardly a risk to adopt Node for building general web-centric applications, provided that your engineering team possesses sufficiently strong Javascript skills. It wasn’t a difficult decision for me two years ago to pick Node as the core technology stack, and would be an even easier one today.
For more screen-shots of the website, click here.

